restTemplate未设置连接数导致服务雪崩问题
背景
昨天发版遇到个线上问题,由于运维操作放量时隔离机器过多,导致只有大概三分之一的机器承载全部流量,等于单台机器的流量突增至正常时候的三倍。前置对外的api服务开始疯狂报错:
ConnectionPoolTimeoutException:Timeout warning for connection from pool
问题分析
连接池满了。查看下相关代码,用了restTemplate去调用另外一个子系统,继续查看关于连接池的信息:
org.apache.http.conn.ConnectionPoolTimeoutException 是 Apache HttpClient 抛出的一种 山异常,表示从连接池获取连接超时。
这种异常通常是由以下原因导致:
1.连接池中没有可用的连接。当请求到达时,如果连接池中没有可用的连接,就会尝试创建新的连接。如果创建连接的速度很慢,或者连接池中的连接已经用完了,就会出现ConnectionPoolTimeoutException 异常。
2.连接池中的连接都被占用。如果连接池中的所有连接都正在被占用,而且没有连接释放回池中,就会导致连接池超时异常。3.请求超时时间设置过短。如果设置的请求超时时间过短,就可能在等待连接的过程中超时。
迅速去查看连接池大小配置了多少,发现并没有进行相关的配置,那默认的就是2,这样远远不够应对当前瞬时的大并发流量的。
问题解决
立刻进行了相关配置:
@Bean
public RestTemplate buildRestTemplate(){final ConnectionKeepAliveStrategy myStrategy = (response, context) -> {return 5 * 1000;//设置一个链接的最大存活时间};MultiThreadedHttpConnectionManager connectionManager = new MultiThreadedHttpConnectionManager();PoolingHttpClientConnectionManager pollingConnectionManager = new PoolingHttpClientConnectionManager(30, TimeUnit.SECONDS);// 总连接数pollingConnectionManager.setMaxTotal(1000);// 同路由的并发数pollingConnectionManager.setDefaultMaxPerRoute(1000);HttpClient httpClient = HttpClientBuilder.create().setConnectionManager(pollingConnectionManager).setKeepAliveStrategy(myStrategy).build();HttpComponentsClientHttpRequestFactory factory = new HttpComponentsClientHttpRequestFactory(httpClient);factory.setConnectTimeout(3000);factory.setReadTimeout(5000);return new RestTemplate(factory);
}
直接设置成了1000,交给测试压测,瞬时200的并发量压测也没有出现ConnectionPoolTimeoutException的问题,看来成功解决了。
restTemplate优化点补充
另外,restTemplate还有个点能够优化。
1. RestTemplate 介绍
RestTemplate和Spring提供的JdbcTemplate类似,对象一旦构建(使用过程中不对其属性进行修改)就是线程安全的,多线程环境下可以安全使用。
2. 场景描述
A系统接口需要访问B系统接口,正常请求时,这部分代码耗时不是很明显(约10ms)。后来,进行接口压力测试,发现请求耗时长达500ms,导致整个接口的tps很难上去,调整线程池参数效果努力无果,后来对请求B系统接口做了内存级别的缓存(guava),tps增长了3倍左右(约500)。
3.问题分析
B系统给出的压测数据显示,单实例接口的tps在1000+,因此初步排除了B系统接口性能差的可能。于是,开始深究系统本身代码可能存在的问题。
最开始的代码编写方式如下:
String url = "xxx.com/api"';
RestTemplate restTemplate = new RestTemplate();
MemeberCardCodeRspDTO result = restTemplate.getForObject(url, MemeberCardCodeRspDTO.class);
System.out.println(result != null ? result.getMsg() : "null");
看上去简单明了,两行代码搞定,非常优雅。后来在组长大大的帮助下,大致定位了问题点,觉得该部分代码可能存在部分性能问题,应该抽取成单实例,即不能每次使用时重新new一个新的对象。改造后的代码为:
@Bean
public RestTemplate buildRestTemplate(){final ConnectionKeepAliveStrategy myStrategy = (response, context) -> {return 5 * 1000;//设置一个链接的最大存活时间};MultiThreadedHttpConnectionManager connectionManager = new MultiThreadedHttpConnectionManager();PoolingHttpClientConnectionManager pollingConnectionManager = new PoolingHttpClientConnectionManager(30, TimeUnit.SECONDS);// 总连接数pollingConnectionManager.setMaxTotal(1000);// 同路由的并发数pollingConnectionManager.setDefaultMaxPerRoute(1000);HttpClient httpClient = HttpClientBuilder.create().setConnectionManager(pollingConnectionManager).setKeepAliveStrategy(myStrategy).build();HttpComponentsClientHttpRequestFactory factory = new HttpComponentsClientHttpRequestFactory(httpClient);factory.setConnectTimeout(3000);factory.setReadTimeout(5000);return new RestTemplate(factory);
}
直接依赖spring bean注解将其定义成单实例对象,其他地方直接属性注入后使用。
4. 性能分析
问题得到解决后,课余时间又对该部分代码做了一个粗略的定量分析,本机跑的数据,还是能比较清晰地得出结论。
private final String url = "xxxx.com/api";
private int loopCount = 400;
private int concurrentThread = 400;
private RestTemplate restTemplate;@BeforeTest
public void init() {final ConnectionKeepAliveStrategy myStrategy = (response, context) -> {return 5 * 1000;//设置一个链接的最大存活时间};PoolingHttpClientConnectionManager pollingConnectionManager = new PoolingHttpClientConnectionManager(30, TimeUnit.SECONDS);// 总连接数pollingConnectionManager.setMaxTotal(1000);// 同路由的并发数pollingConnectionManager.setDefaultMaxPerRoute(1000);HttpClient httpClient = HttpClientBuilder.create().setConnectionManager(pollingConnectionManager).setKeepAliveStrategy(myStrategy).build();HttpComponentsClientHttpRequestFactory factory = new HttpComponentsClientHttpRequestFactory(httpClient);factory.setConnectTimeout(3000);factory.setReadTimeout(5000);restTemplate = new RestTemplate(factory);
}
@Test
public void testHttp1() {long start = System.currentTimeMillis();ExecutorService executor = Executors.newFixedThreadPool(concurrentThread);for (int i =0 ; i< loopCount; i++){executor.submit(() -> {MemeberCardCodeRspDTO result = restTemplate.getForObject(url, MemeberCardCodeRspDTO.class);System.out.println(result != null ? result.getMsg() : "null");});}try {executor.shutdown();executor.awaitTermination(30, TimeUnit.MINUTES); // or longer.} catch (InterruptedException e) {e.printStackTrace();}long time = System.currentTimeMillis() - start;System.out.printf("Tasks1 took %d ms to run%n", time);
}@Test
public void testHttp2() {long start = System.currentTimeMillis();ExecutorService executor = Executors.newFixedThreadPool(concurrentThread);for (int i =0 ; i< loopCount; i++){executor.submit(() -> {RestTemplate restTemplate = new RestTemplate();MemeberCardCodeRspDTO result = restTemplate.getForObject(url, MemeberCardCodeRspDTO.class);ystem.out.println(result != null ? result.getMsg() : "null");});}try {executor.shutdown();executor.awaitTermination(30, TimeUnit.MINUTES); // or longer.} catch (InterruptedException e) {e.printStackTrace();}long time = System.currentTimeMillis() - start;System.out.printf("Tasks2 took %d ms to run%n", time);
}
调整threads数量,跑了6组数据,结果对比如下:
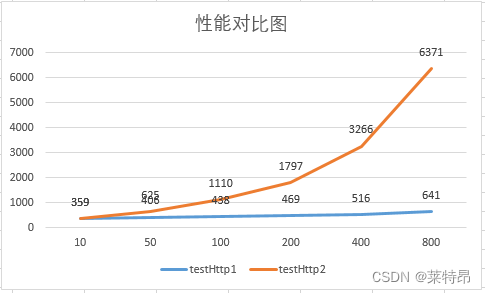
图中比较清晰的可以看出,优化过后的代码性能提升比较明显,且随着并发任务数增加,耗时波动不会太大。
5. 问题总结
第三方库提供的各种方便的类,简化了编码复杂度,方便了开发者。使用不恰当时,细微的编码可能埋藏着大的隐患。
精雕细琢,精益求精。