Arrow kernel设计与实现
Arrow kernel设计与实现
目录
1.什么是kernel
2.Kernel盘点
3.执行计算流
4.如何实现Kernel执行三步曲?
1.什么是kernel
最近在实现几个自定义的Arrow Kernel,需要非常了解Arrow源码,里面的代码设计是什么样子,怎么快速上手,如何高度自定制开发,里面有哪些比较有意思的设计等等问题,将在本文一一展开。
Arrow是一个列存格式,同时也有一个streaming execution engine,整个执行器的Plan节点,可以拆分为Source、Sink、Agg、Proj、Filter等等。
以Agg为例,对于PostgreSQL来说Agg可以分为两阶段,PartialAgg与FinalAgg,而在Arrow这边只有一个mean运算,也就是一次聚集。
两阶段聚集的逻辑为:以avg为例
第一阶段
在各个节点进行计算,先计算出各个节点的sum、count
第二阶段
在master节点上收到各个子节点的sum、count,然后每个累加之后,做除法,得到avg。
对于Arrow来说,使用Agg便是往AggOption里面设置一个mean函数,这个函数直接得到的是一个avg结果,跟我们的预期不符,因此需要拆分为:
avg_trans(第一阶段)
输入为任意类型,输出为struct
avg_final(第二阶段)
输入为struct
由于Arrow在每个阶段支持consume->merge->finalize,所以我们可以在第二阶段做merge操作,finalize阶段直接计算avg结果,这样变得非常容易了。
当然,里面还有很多实现细节,诸如:struct如何生成、如何识别struct输入,struct如何进行计算,里面的类型转换是什么样子呢?
在写这篇文章之前,发现自己理解的比较肤浅,写完之后,一梳理全都顺了,好东西都是要分享的,期待大家一起交流,共同进步~
2.Kernel盘点
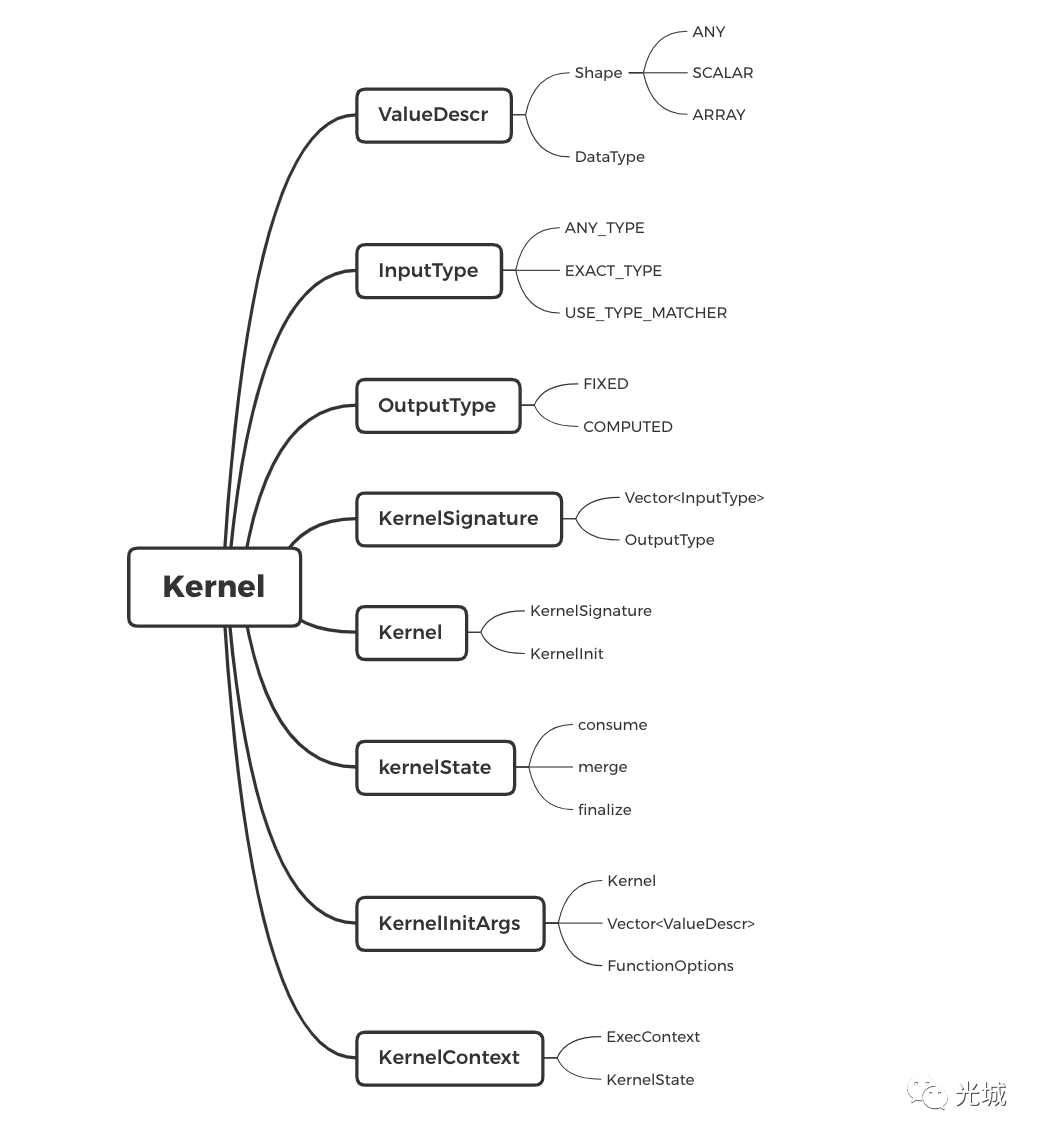
1.值描述符(ValueDescr)
包含数据类别(Shape)与数据类型(DataType)。
数据类别:分为数组、标量值、任意类型(前面两者之一)。
数据类型抽象:DataType为所有类型的基类,例如:定长、嵌套类型等。
对于一个数据,总是有类型的,那么在Arrow中就有一个对应的ValueDesc,用来描述输入数据的类型是什么,由于在向量化中传入的数据可以为嵌套类型、高精度类型等等,而不仅仅包含传统的C类型,所以需要自定义一个ValueDescr用来描述这个结构。
2.输入数据类型(InputType)
允许我们根据输入的数据类型去决定如何提取输入数据的行为。通常比较直接的就是你传递的是什么,输入就是什么,那么这被称为ANY_TYPE,对应ValueDescr的Any;当需要自定义输入时,我们可以选用EXACT_TYPE,例如:我现在输入的是int类型,但是我想将其转为uint,那么便可以选用这种;最后一种情况就是高度自定义,可以自己定义一个类型匹配器,决定输入的类型是否匹配,这种称为USE_TYPE_MATCHER。
3.输出类型(OutputType)
就更加有意思了,它划分为固定输出类型与可被计算的输出类型。
固定输出类型
你给我传递什么,我就用什么作为输出类型。
可被计算输出类型
你给我传递一个解析器,根据你传递的类型(一般为输入类型)去生成一个输出类型。
不得不说这个解析器设计简直牛逼!
举个场景:基于PG的逻辑我们需要做AGG两阶段聚集,根据输入的int类型数据,第一阶段产生的是struct
4.内核签名(KernelSignature)
内核签名表示内核(kernel)当中计算的数据签名,设计思想为:你给我一堆输入类型,一个输出类型。
⚠️输入类型可以是多个,输出是一个,为何这样设计呢?
举个例子:我现在要计算count(bool) 有一列是bool,我要计算count(bool),得出的结果是什么?
毋庸置疑是一个int/uint,那么本身是int的输出就还是int,这样需求不就来了,存在多对一关系。
实际实现中,内核签名还需要对输入类型做hash保证唯一性。
5.内核(Kernel)
内核是其他所有计算内核的基类,定义了公共拥有的内容。在Kernel当中定义了内核签名与初始化。
内核签名就不说了,一个内核肯定需要知道当前输入数据与输出数据张什么样子。
内核初始化,需要重点讲一下,每个计算内核都需要做自己的事情,那么如何保证这一点呢?
这便是KernelInit的强大之处!简单来说,Kernel提供了统一的初始化接口,内部InitAll会初始化所有的Kernel,每次初始化会调用对应Kernel的KernelInit函数,签名见后面,每个内核要做自己的事情可以在KernelInit中去做,怎么保证这一点?
便是通过KernelState来实现的。
using KernelInit = std::function>(KernelContext*, const KernelInitArgs&)>; KernelState定义了一个接口,是一个opaque类型。每个计算内核只需要继承KernelState便可以自己定义的KernelState。
struct ARROW_EXPORT KernelState {virtual ~KernelState() = default;
};例如:ScalarAggregator相关:
struct ScalarAggregator : public KernelState { };这里之所以称为ScalarAggregator,是因为返回值是标量,而不是输入是标量,输入可以是数组/标量的。另外一种普遍的Agg就是group by,这里被称为HashAgg。
在每个Init时,用户可以根据传入的参数(KernelInitArgs)与上下文(KernelContext)来生成自己的KernelState。接下来我们分别讲解这里提到的一些内容。
6.内核参数( KernelInitArgs)
内核参数非常简单,kernel与inputs前面都介绍过了,这里直接说这两个功能:
kernel
一般用来提取输出类型,在注册阶段会把输入与输出类型注册到KernelSignal中,我们知道OuputType可以是解析器,那么怎么提取呢?
这里可以通过kernel来获取,例如:
ARROW_ASSIGN_OR_RAISE(auto out_type,args.kernel->signature->out_type().Resolve(ctx, args.inputs));inputs
一堆ValueDesc,表示输入数据类型签名。
options
FunctionOptions这个就比较复杂了,后面专门讲解,可以简单理解为存储计算函数,例如现在要计算sum(i),那么这里便是sum函数相关的一些信息。
struct KernelInitArgs {const Kernel* kernel;const std::vector& inputs;const FunctionOptions* options;
}; 7.内核上下文( kernelContext)
内核上下文用来执行特定KernelState。
里面包含了执行上下文(ExecContext)与内核状态(KernelState)。
执行上下文跟执行器相关了,后面再详细阐述。
接下来,我们用实际的例子来深入内核。
3.执行计算流
在这里我们将回答几个问题,我们在一个Plan里面添加了节点经常需要设置Option,为何要设置呢?如果不设置会怎么样呢?
答案是如果不设置那就找不到你的计算函数了,例如:avg会写入到option里面,在构建AggNode时,将会从option里面找到Agg函数,option里面的agg可能是多个,所以要一个个遍历,然后拿到每个agg的输入描述结构列表,从Kernel签名会对其进行Match,随后构建KernelContext,构建KernelInitArgs,此时Kernel准备工作就绪,调用我们的Init函数,此时会初始化得到我们想要的State,把这个State丢进context里面,下次执行从context进行获取即可,最后需要通过Kernel签名中的OutputType拿到对应的Resolver,提取出Out类型,构造出Agg节点放入plan中。
以上便是一个完整的添加节点到plan当中的流程。
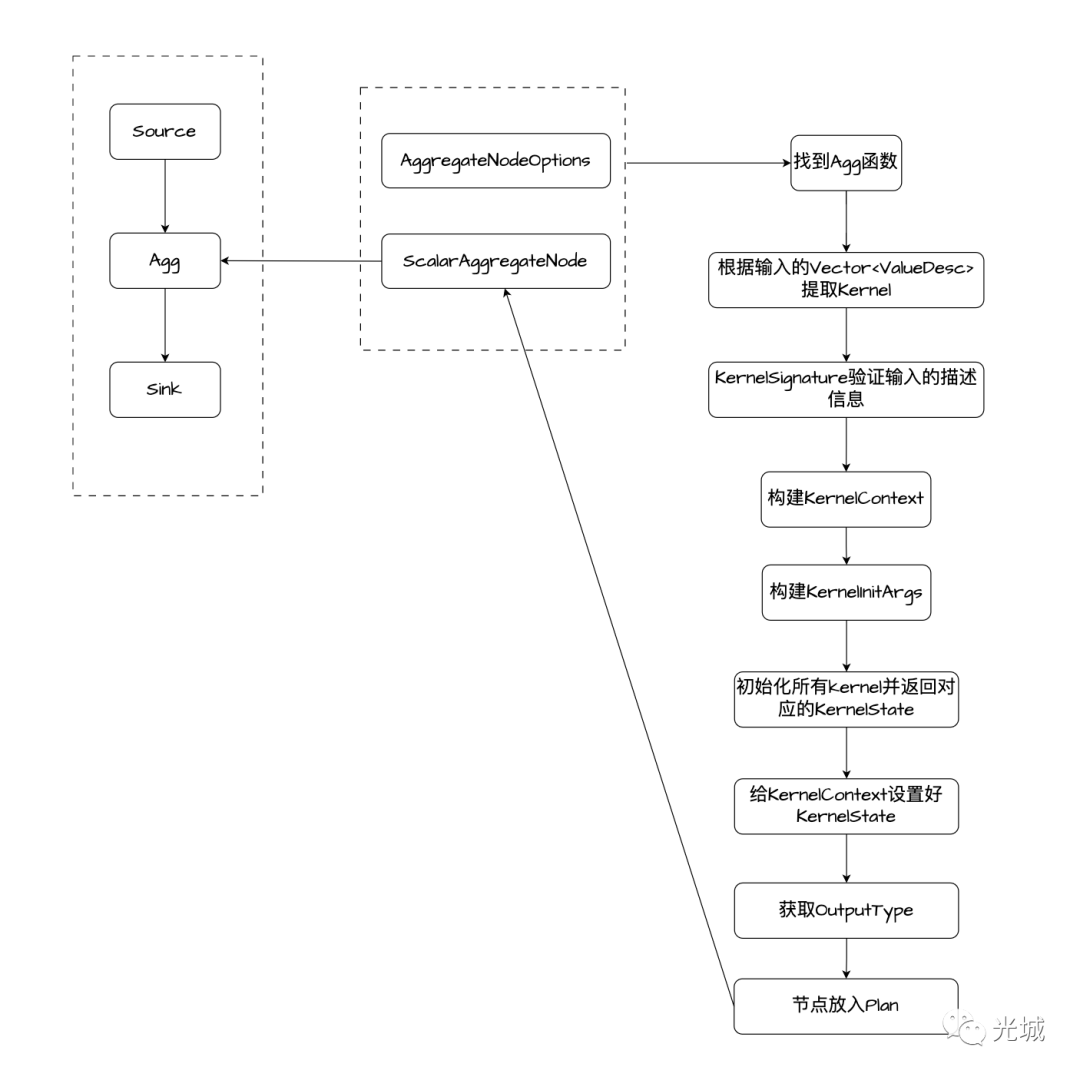
添加完节点,那肯定要执行,所以当执行器运行起来后,会通过前面的KernelContext执行state的三步曲。依次调用consume、merge、finalize。
对应如下图所示:
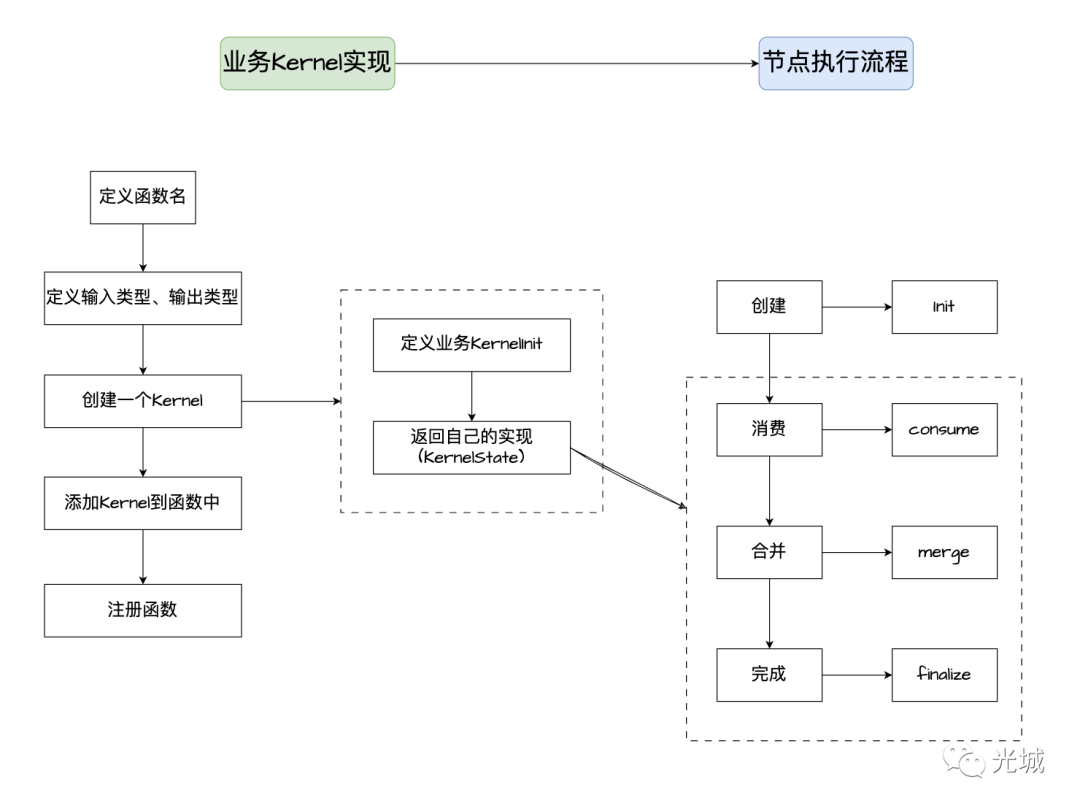
4.如何实现Kernel执行三步曲?
以Sum为例:
Consume阶段,我们需要消费数据,数据可以是一个数组也可以是一个标量,所以在代码中都做了处理,下面呆木进行了本部分删减,只展示核心逻辑。
Status Consume(KernelContext*, const ExecBatch& batch) override {if (batch[0].is_array()) {const auto& data = batch[0].array();this->count += data->length - data->GetNullCount();this->sum += SumArray(*data);} else {const auto& data = *batch[0].scalar();this->count += data.is_valid * batch.length;this->sum += internal::UnboxScalar::Unbox(data) * batch.length;}}return Status::OK();
} 2.Merge
两两累加。
Status MergeFrom(KernelContext*, KernelState&& src) override {const auto& other = checked_cast(src);this->count += other.count;this->sum += other.sum;this->nulls_observed = this->nulls_observed || other.nulls_observed;return Status::OK();
} 3.Finalze
由于Sum是不需要三阶段的,所以上述Merge完就是结果了,这里只是赋值,不做处理,但是对于mean之类的,需要做计算。
Status Finalize(KernelContext*, Datum* out) override {if ((!options.skip_nulls && this->nulls_observed) ||(this->count < options.min_count)) {out->value = std::make_shared(out_type);} else {out->value = std::make_shared(this->sum, out_type);}return Status::OK();
} 本节完~
上一篇:链表 算法
下一篇:C++019-C++暴力枚举