决策曲线拆解分析兼随机森林DCA绘制
创始人
2025-05-30 19:45:39
临床决策曲线(DCA)解析兼绘制随机森林的DCA曲线(R)
临床决策曲线的独特作用
- 协助决定阈值;cost-benefit 比值的概念和净收益的概念对临床决策阈值的选择都有重要的参考作用。
- 协助选择模型,通常区分度和校准度是评价模型和选择模型的标准,这两个参数越高的模型越好,但是在实际情况下,往往是一个模型仅有一方面比另外一个模型好,那么这种情况下该选择哪个模型就是一个问题,决策曲线将有助于模型的选择。
关于DCA的几个观念
- DCA曲线可以用于预测模型、检验marker等实验中。
- 建议使用DCA确定一个阈值范围而不是单个阈值。
- 明确预测模型使用的后续具体的检查或者治疗,比如某某检查或者某某手术等。
cost-benefit比值的概念
- cost 的意思是,检查或者手术本身的不适和副作用;
- benefit的意思是,检查或者手术的诊断和治疗作用;
- 临床上两者往往不是等同的, 一般情况下benefit会大于cost。
- 在DCA中,cost-benefit比值和选择的概率密切相关,比如如果选择的阈值概率为0.1(0.1以上接受检查或者治疗),那么cost-benefit比值为1:9,横坐标轴下的标线就表示出cost-benefit比值。选择阈值为0.1代表了一种考量,即我们愿意检查或者治疗10个人(至多),其中有1个获得了应有的检查或者治疗。在临床上,选择决策阈值之前,可以问这样的问题“你愿意接受检查或者治疗多少人而其中有1个得到了所需的检查或治疗?”,将有助于确定阈值。
净收益概念
- 净收益是DCA的纵坐标,DCA中的treat all曲线和模型曲线需要计算净收益,且两者的计算公式稍微有些区别。下面是treat all 曲线的净收益计算方法,实际上是使用真实值(而不是预测值)来计算的。
#引用自https://blog.csdn.net/qq_48321729/article/details/123241746
def calculate_net_benefit_all(thresh_group, y_label):net_benefit_all = np.array([])tn, fp, fn, tp = confusion_matrix(y_label, y_label).ravel()total = tp + tnfor thresh in thresh_group:#阈值net_benefit = (tp / total) - (tn / total) * (thresh / (1 - thresh))net_benefit_all = np.append(net_benefit_all, net_benefit)return net_benefit_all以下是模型曲线净收益的计算公式。可以看到两者是略有区别的。
#引用自https://blog.csdn.net/qq_48321729/article/details/123241746
def calculate_net_benefit_all(thresh_group, y_label):net_benefit_all = np.array([])tn, fp, fn, tp = confusion_matrix(y_label, y_label).ravel()total = tp + tnfor thresh in thresh_group:net_benefit = (tp / total) - (tn / total) * (thresh / (1 - thresh))#公式net_benefit_all = np.append(net_benefit_all, net_benefit)return net_benefit_all- 从以上公式中也可以看出,只要知道模型预测的概率就可以画出DCA曲线,而treat all曲线和模型无关,所以各种预测模型的treat all 曲线都是相同的,这样我们就可以绘制出随机森林等各种模型的DCA。
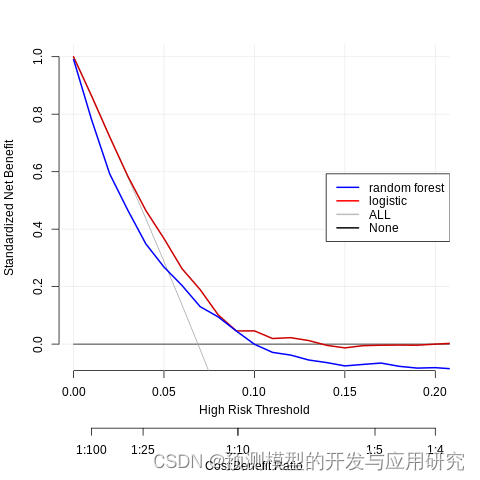
绘制随机森林模型的DCA
目前为止,官方只给出了线性模型(逻辑回归和COX)的DCA绘制方法,这一点是有点奇怪的,可能有些方面不适合向随机森林这样的模型(可能是其中的某些关键元素只能用线性模型来解释),但是从技术层面来看,各种模型都可以制作DCA曲线。
- 线性模型:逻辑回归或者cox回归有现成的R包(rmda)可以用于绘制DCA。
- 从上面的净获益的计算公式可以看出,只要有预测概率就可以计算,所以理论上所有的模型都可以计算净获益,也就可以制作DCA曲线,所以,计算净收益用到的是预测概率,所以模型的预测概率与实际概率的符合程度(校准度)是重要的。
- 随机森林模型:理论上我们只要可以得到阈值(X轴)和净收益(Y轴)的数据,我们就可以绘制出DCA曲线。。
-
考虑到上面所述“奇怪”的情况,同时绘制出线性模型的DCA作为参考,可能是比较妥当的。
-
制作中遇到一个问题,就是“该使用全部数据,训练数据集还是测试数据集来绘制DCA曲线呢?”。对照线性模型的情况来看,应该使用全部数据集来绘制DCA曲线,那麽我们就要使用训练出的模型来预测整个数据集的概率,这会产生overfit的疑虑,所以目前觉得使用交叉验证的方法来获得整个数据集的预测概率是比较妥当的。
-
这里使用了rmda官方的包作为基础绘制,在上面添加random forest 的DCA曲线的方式,比其它的方式更加简洁。
-
绘制的详细代码可以参照链接(https://www.heywhale.com/notebooks/run/6413b2941c8c8b518ba04e52?label=62412710e2ca7e0017eaff45&image=63aa8edc230abea285abb899¬ebook=6413b294530f9c6c19267ed6&beta=1),一键运行。
-
相关内容
热门资讯
贺博生:12.17黄金原油今日...
投资本身没有风险,失控的投资才有风险。不要用你的侥幸去挑战行情,运气这东西是有,碰上一次别再去奢望第...
HashKey港股上市:市值1...
雷递网 雷建平 12月17日 亚洲区域性数字资产在岸平台HashKey Holdings(股票代码:...
人行自贡市分行:信用“金钥匙”...
“太好了!无抵押、无担保,从申请到拿到信用贷款,只用了5天,资金流信息平台真是解了我们的燃眉之急。”...
沐曦股份高开568.83%,一...
新闻荐读 17日,继摩尔线程之后,“国产GPU第二股”沐曦股份正式登陆科创板。 上市首日,沐曦股份高...
润健股份等在上海成立能源科技公...
雷达财经讯,天眼查App显示,近日,润智信科能源科技(上海)有限公司成立,法定代表人为严从东,注册资...