(一)大数据实战——hadoop的基本概念与组成
前言
本节内容是大数据开篇的内容,主要介绍一下大数据的相关概念,以及hadoop组件的组成部分及架构,内容我们主要以hadoop3为例。hadoop主要解决海量数据的存储和海量数据的分析计算问题。为了便于我们理解后续的学习内容,本节内容也算是作者的学习笔记,不足之处,还望各位读者多多包涵,小白一枚。
正文
- 大数据的特点
- Volume(大量):企业的数据量已经接近EB量级
- Velocity(高速):实现对海量数据的快速处理
- Variety(多样): 数据分为结构化数据和非结构化数据(日志、音频、视频、图 片、地理位置)
- Value(低价值密度):从海量数据中获取有价值的数据
- hadoop的优势
- 高可靠性:Hadoop底层使用多数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。
- 高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
- 高效性:在MapReduce的思想下,Hadoop可以实现并行工作,以加快任务的处理速度。
- 高容错性:能够自动将失败的任务重新分配。
- hadoop的组成
1.HDFS分布式文件存储系统
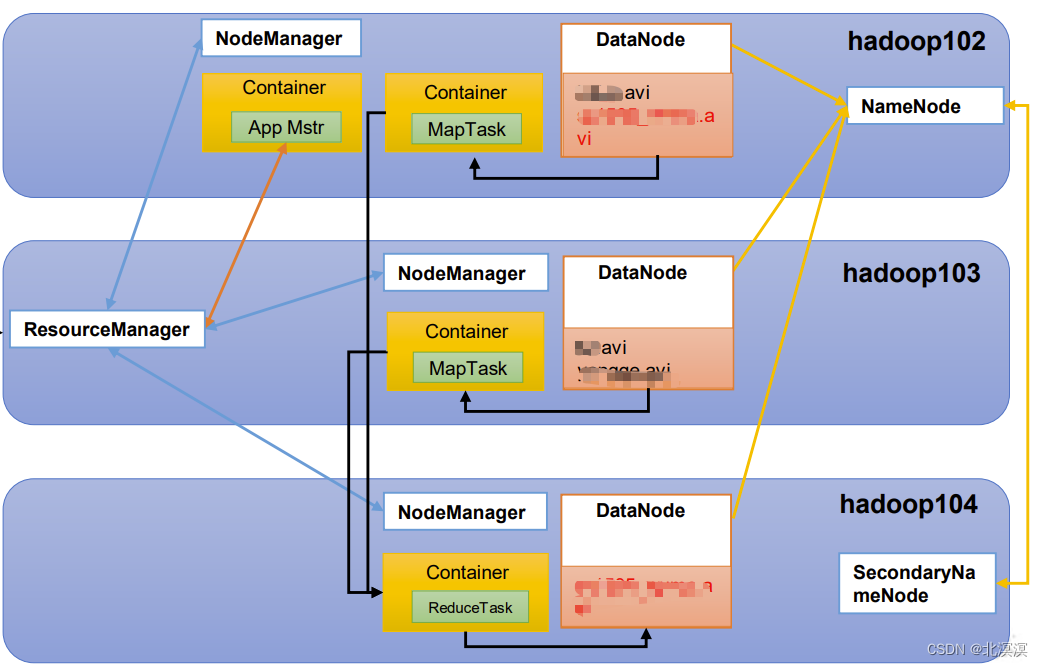
- NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、 文件权限),以及每个文件的块列表和块所在的DataNode等。
- DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
- Secondary NameNode(2nn):每隔一段时间对NameNode元数据备份。
2.YARN资源协调器
- ResourceManager(RM):管理整个集群资源(内存、CPU等)
- NodeManager(NM):管理单个节点服务器资源
- ApplicationMaster(AM):单个运行的任务
- Container:容器,相当一台独立的服务器,里面封装了任务运行所需要的资源,如内存、CPU、磁盘、网络等
3.MapReduce计算
- Map阶段并行处理输入数据
- Reduce 阶段对 Map 结果进行汇总
- HDFS、YARN、MapReduce三者之间的关系
结语
本节内容到这里就结束了,我们下期见。。。。。。
下一篇:Scala环境安装【傻瓜式教程】