小白学Pytorch系列--Torch.nn API (1)
小白学Pytorch系列–Torch.nn API (1)

| 方法 | 注释 |
|---|---|
| Parameter | 一种被认为是模参数的张量 |
| UninitializedParameter | 未初始化的参数 |
| UninitializedBuffer | 未初始化的缓冲区 |
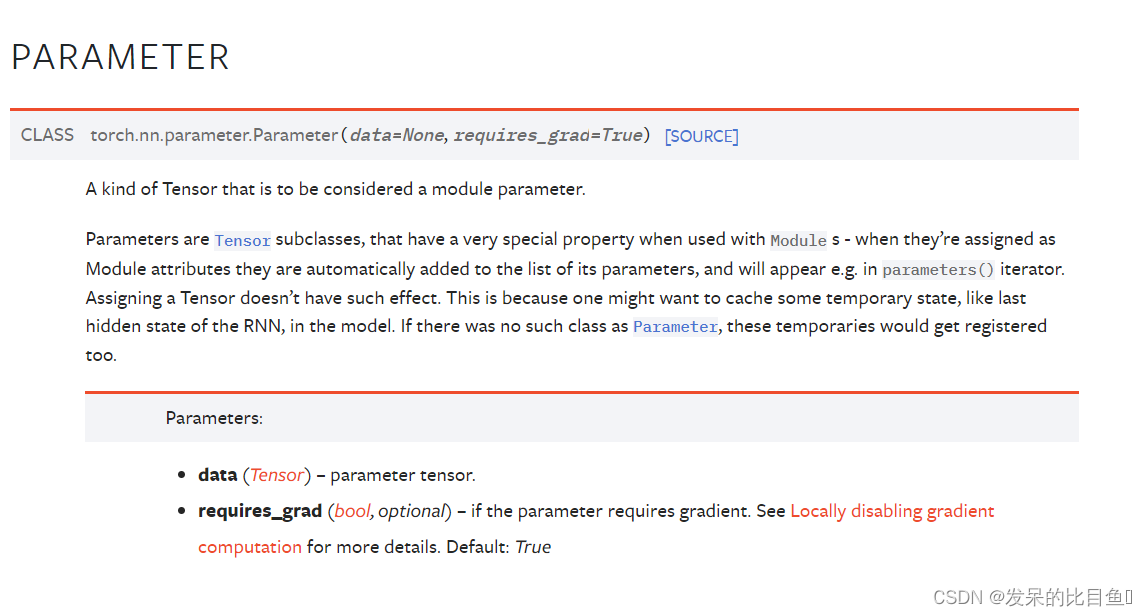
Parameter
一种被认为是模参数的张量。
参数是Tensor的子类,当与Module s一起使用时,它们有一个非常特殊的属性——当它们被重新赋值为Module属性时,它们会自动添加到它的参数列表中,并将出现在Parameters()迭代器中。分配一个张量没有这样的效果。这是因为人们可能想要在模型中缓存一些临时状态,比如RNN的最后一个隐藏状态。如果没有Parameter这样的类,这些临时对象也会被注册。
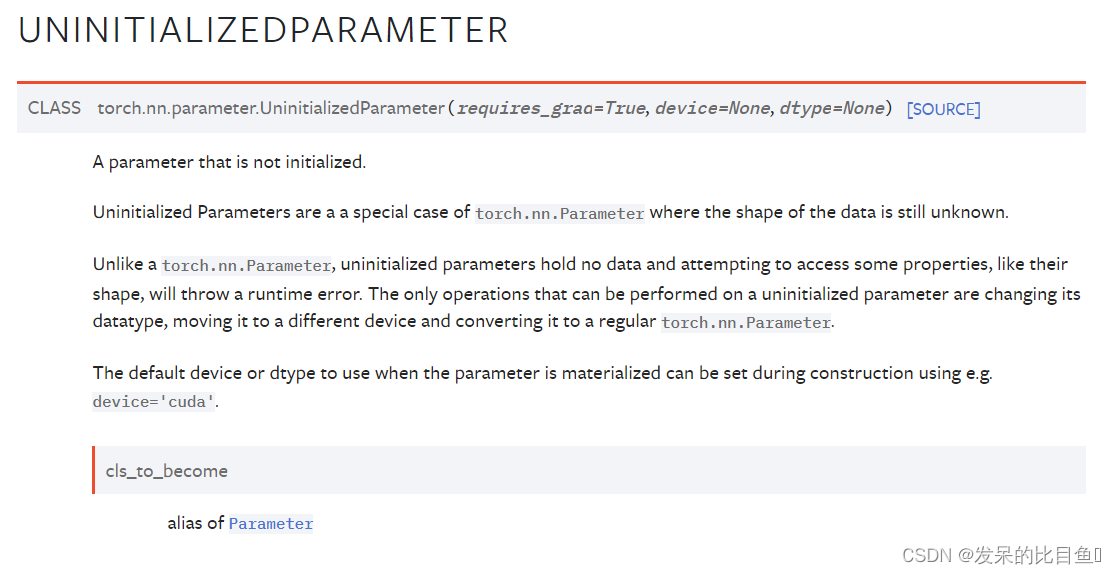
UninitializedParameter
Parameter别名
未初始化参数是torch.nn.Parameter的特殊情况,其中数据的形状仍然未知。
与torch.nn.Parameter不同,未初始化的参数不包含任何数据,并且尝试访问某些财产(如其形状)将引发运行时错误。唯一可以对未初始化的参数执行的操作是更改其数据类型,将其移动到其他设备,并将其转换为常规torch.nn.parameter。
参数具体化时使用的默认设备或数据类型可以在构造过程中使用例如device=“cuda”进行设置。
UninitializedBuffer
与torch.Tensor不同,未初始化的参数不包含任何数据,并且尝试访问某些属性(如其形状)将引发运行时错误。唯一可以对未初始化的参数执行的操作是更改其数据类型,将其移动到不同的设备,并将其转换为常规torch.Tensor。
缓冲区具体化时使用的默认设备或数据类型可以在构建过程中使用例如device=“cuda”进行设置。
Containers
| 方法 | 注释 |
|---|---|
| Module | 所有神经网络模块的基类 |
| Sequential | 顺序容器 |
| ModuleList | 将子模块保存在列表中 |
| ModuleDict | 保存字典中的子模块 |
| ParameterList | 在列表中保存参数 |
| ParameterDict | 在字典中保存参数 |
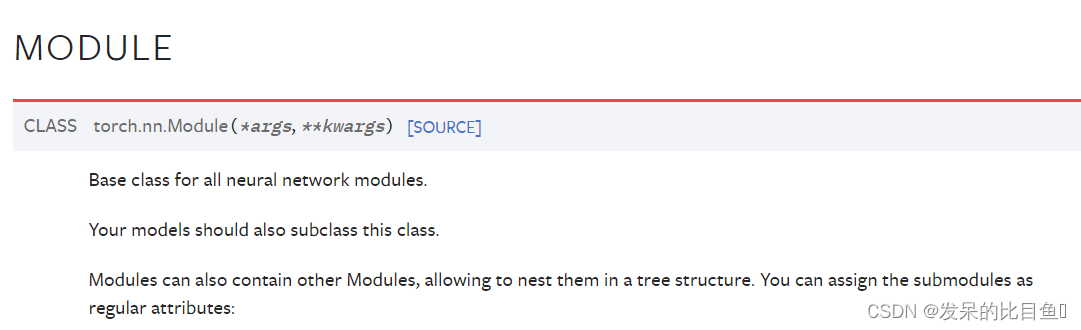
Module
所有神经网络模块的基类。
你的模型也应该子类化这个类。
模块还可以包含其他模块,允许将它们嵌套在树结构中。您可以将子模块分配为常规属性
变量
training - 布尔值表示该模块是处于训练模式还是评估模式
方法
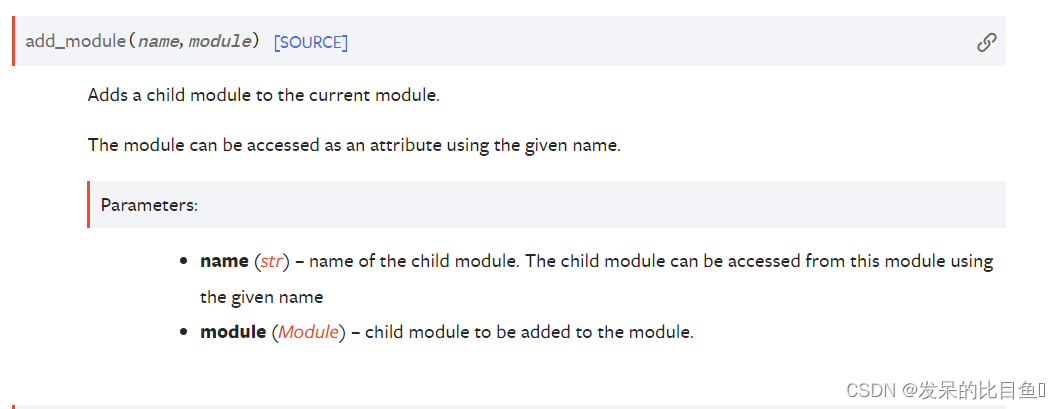
add_module
将子模块添加到当前模块。
可以使用给定的名称将模块作为属性进行访问。
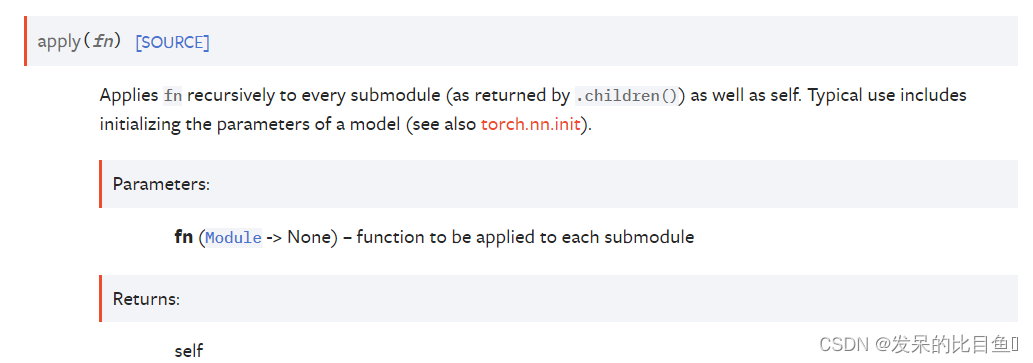
apply
递归地将fn应用于每个子模块(由.children()返回)以及self。典型的用法包括初始化模型的参数(另请参见torc.nn.init)。
>>> @torch.no_grad()
>>> def init_weights(m):
>>> print(m)
>>> if type(m) == nn.Linear:
>>> m.weight.fill_(1.0)
>>> print(m.weight)
>>> net = nn.Sequential(nn.Linear(2, 2), nn.Linear(2, 2))
>>> net.apply(init_weights)
Linear(in_features=2, out_features=2, bias=True)
Parameter containing:
tensor([[1., 1.],[1., 1.]], requires_grad=True)
Linear(in_features=2, out_features=2, bias=True)
Parameter containing:
tensor([[1., 1.],[1., 1.]], requires_grad=True)
Sequential((0): Linear(in_features=2, out_features=2, bias=True)(1): Linear(in_features=2, out_features=2, bias=True)
)
bfloat16
将所有浮点参数和缓冲区强制转换为bfloat16数据类型。
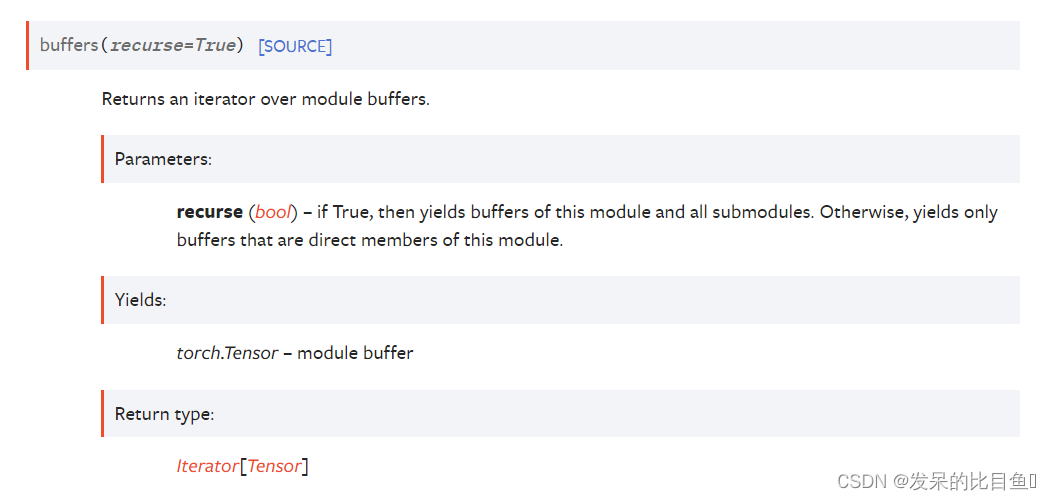
buffers
返回模块缓冲区上的迭代器。
>>> for buf in model.buffers():
>>> print(type(buf), buf.size())
(20L,)
(20L, 1L, 5L, 5L)
cpu()
将所有模型参数和缓冲区移动到CPU。
cuda(device=None)
将所有模型参数和缓冲区移动到GPU。
这也使得关联的参数和缓冲区不同的对象。因此,如果模块在优化时将在GPU上运行,则应在构建优化器之前调用它。
double()
将所有浮点参数和缓冲区转换为双数据类型。
eval()
将模块设置为评估模式。
这只对某些模块有任何影响。有关特定模块在训练/评估模式下的行为细节,请参见特定模块的文档,如果它们受到影响,例如Dropout、BatchNorm等。
这相当于self.train(False)。
extra_repr()
设置模块的额外表示形式
要打印自定义的额外信息,您应该在自己的模块中重新实现此方法。单线字符串和多线字符串都是可以接受的。
float()
将所有浮点参数和缓冲区强制转换为浮点数据类型。
*forward(input)
定义每次调用时执行的计算。
应该被所有子类覆盖。
get_buffer(target)
返回目标给定的缓冲区(如果存在),否则抛出错误。
有关此方法的功能以及如何正确指定目标的更详细解释,请参阅get_submodule的docstring。
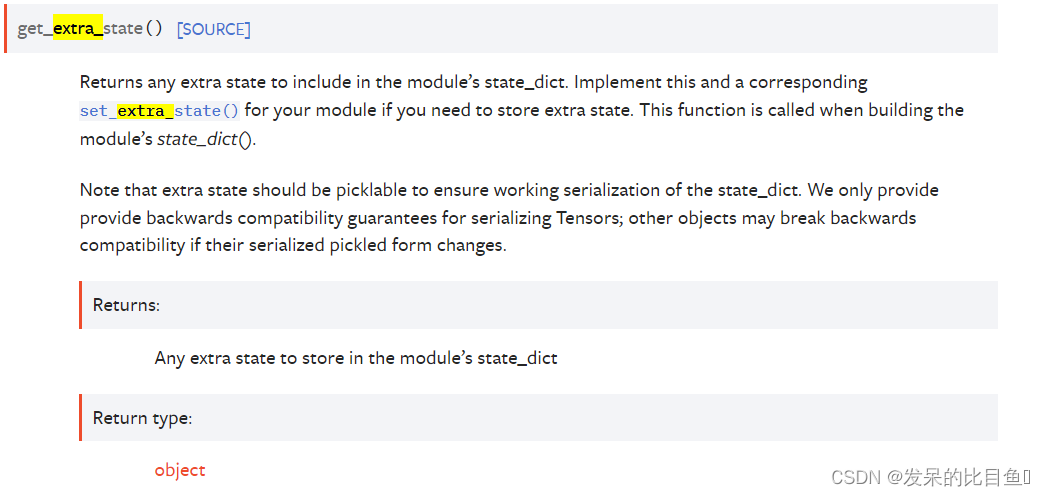
get_extra_state()
返回要包含在模块的state_dict中的任何额外状态。如果您需要存储额外的状态,请为您的模块实现此功能和相应的set_extra_state()。在构建模块的state_dict()时调用此函数。
请注意,额外的状态应该是可拾取的,以确保state_dict的工作序列化。我们只为序列化张量提供向后兼容性保证;如果其他对象的序列化pickle形式发生更改,则可能会破坏向后兼容性。
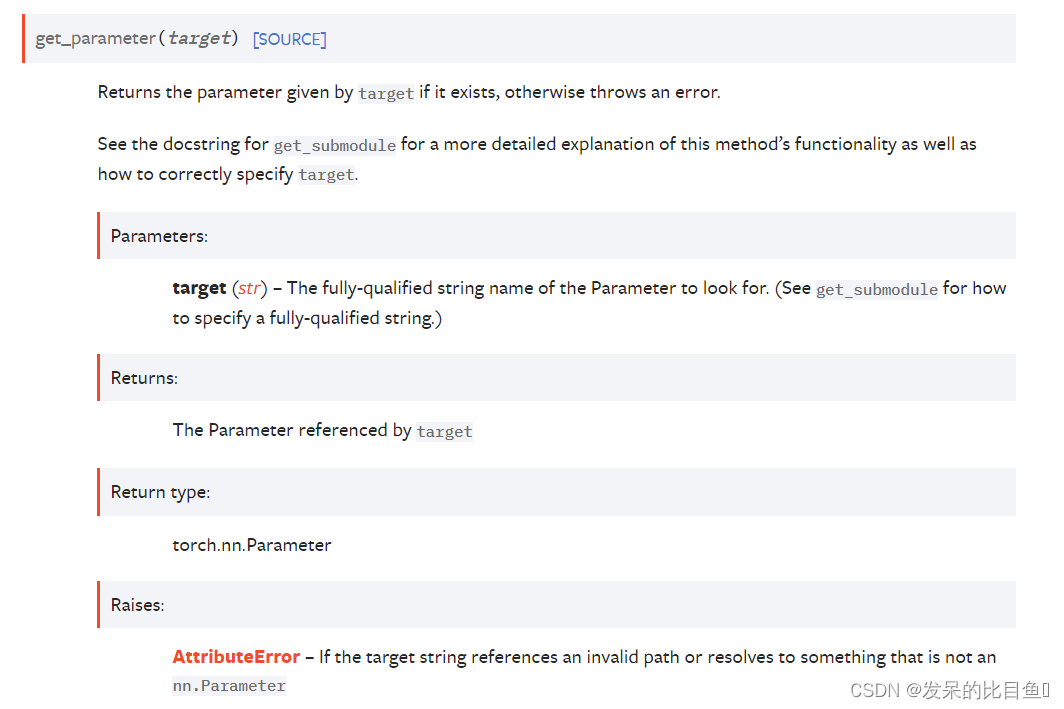
get_parameter(target)
返回目标给定的参数(如果存在),否则抛出错误。
有关此方法的功能以及如何正确指定目标的更详细解释,请参阅get_submodule的docstring。
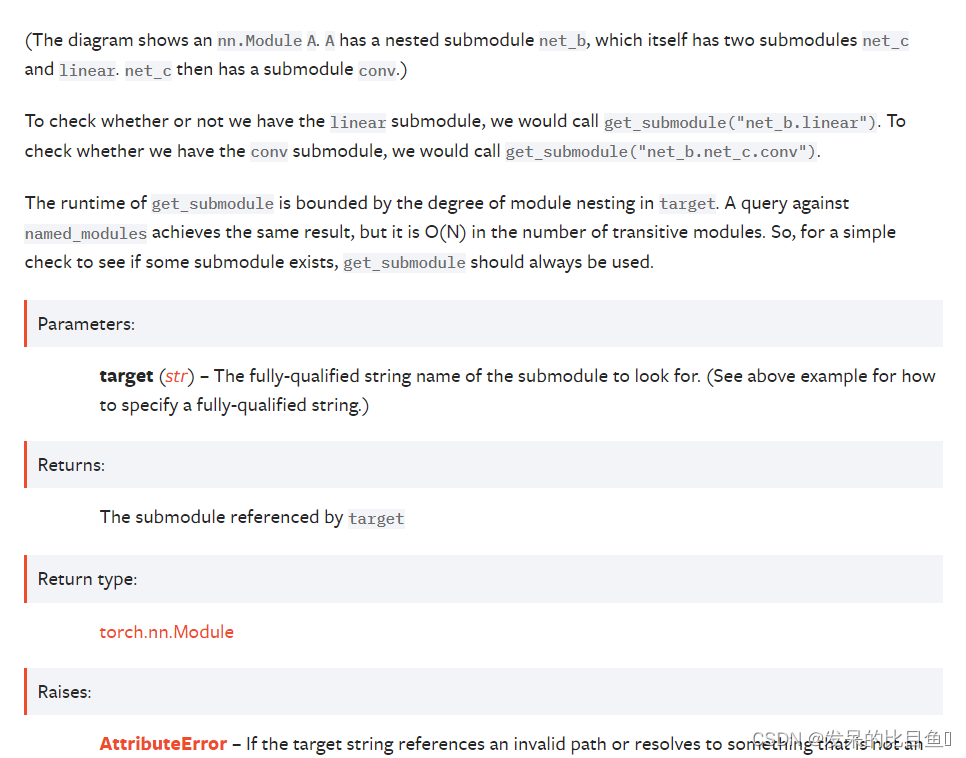
get_submodule(target)
如果存在则返回 target 给定的子模块,否则抛出错误。
例如,假设您有一个如下所示的 nn.Module A:
A((net_b): Module((net_c): Module((conv): Conv2d(16, 33, kernel_size=(3, 3), stride=(2, 2)))(linear): Linear(in_features=100, out_features=200, bias=True))
)
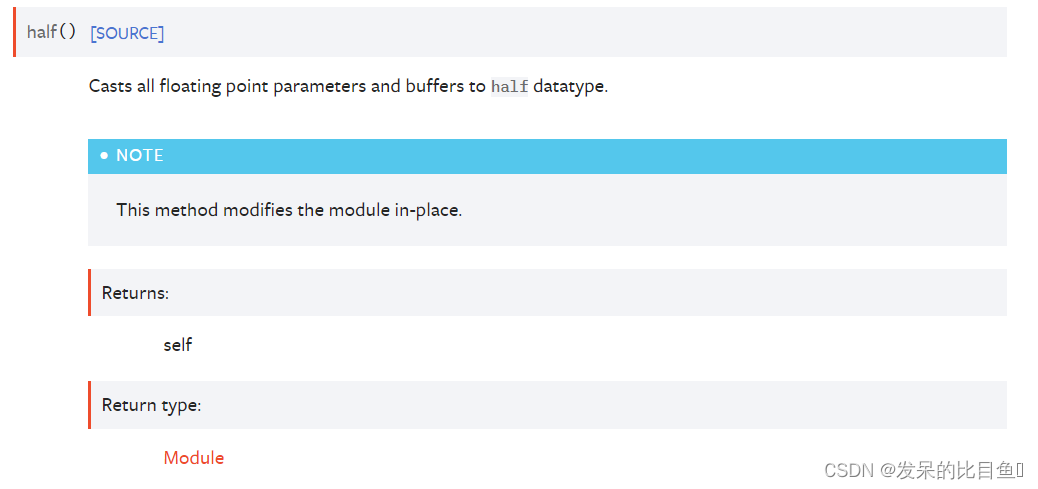
half()
将所有浮点参数和缓冲区转换为半数据类型。
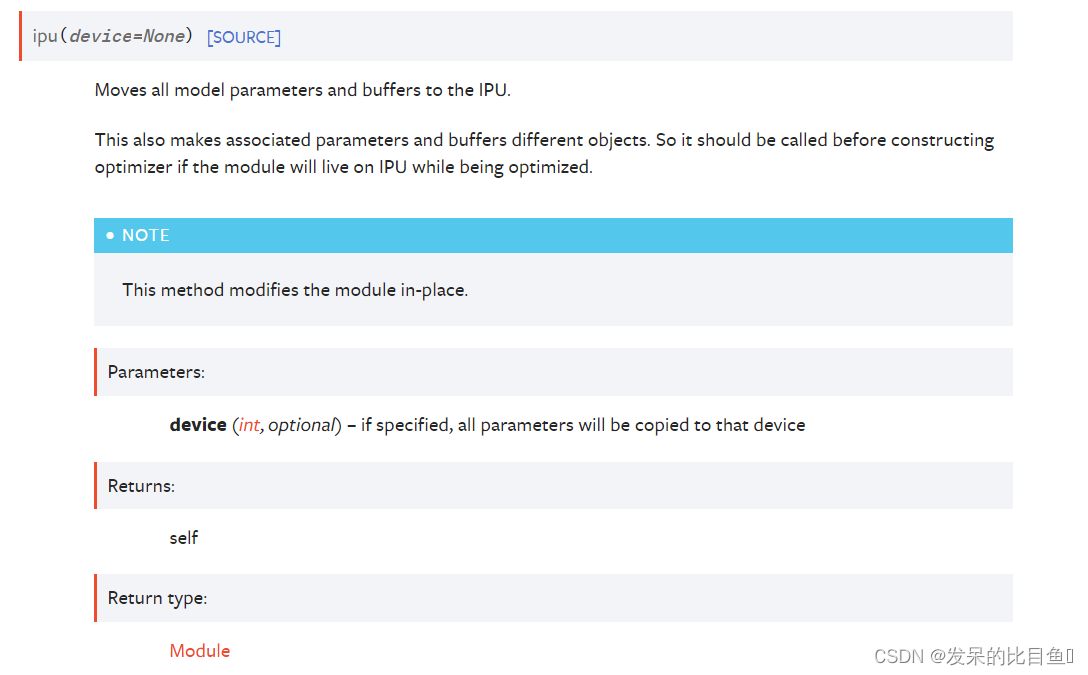
ipu(device=None)
将所有模型参数和缓冲区移动到IPU。
这也使得关联的参数和缓冲区不同的对象。因此,如果模块在优化时将驻留在IPU上,则应在构造优化器之前调用它。
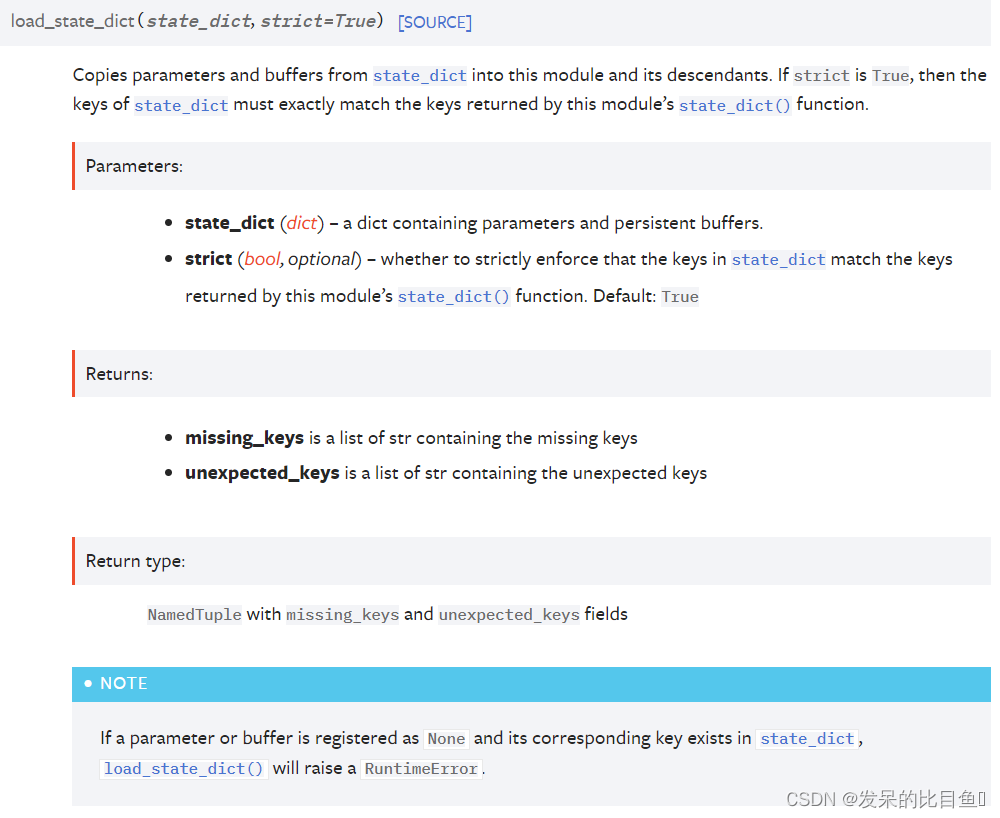
load_state_dict
将参数和缓冲区从state_dict复制到此模块及其子模块中。如果strict为True,则state_dict的键必须与此模块的state_dict()函数返回的键完全匹配。
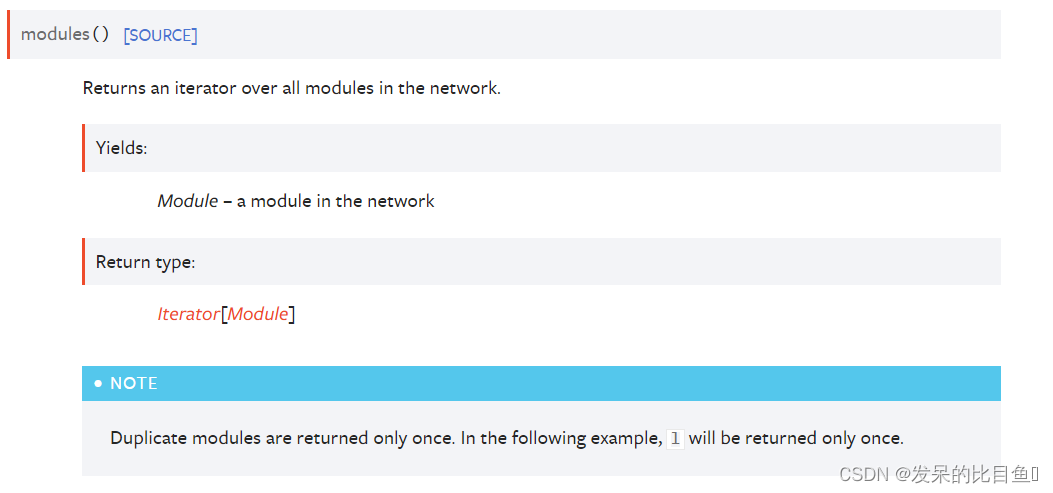
modules()
返回网络中所有模块的迭代器。
>>> l = nn.Linear(2, 2)
>>> net = nn.Sequential(l, l)
>>> for idx, m in enumerate(net.modules()):
... print(idx, '->', m)0 -> Sequential((0): Linear(in_features=2, out_features=2, bias=True)(1): Linear(in_features=2, out_features=2, bias=True)
)
1 -> Linear(in_features=2, out_features=2, bias=True)
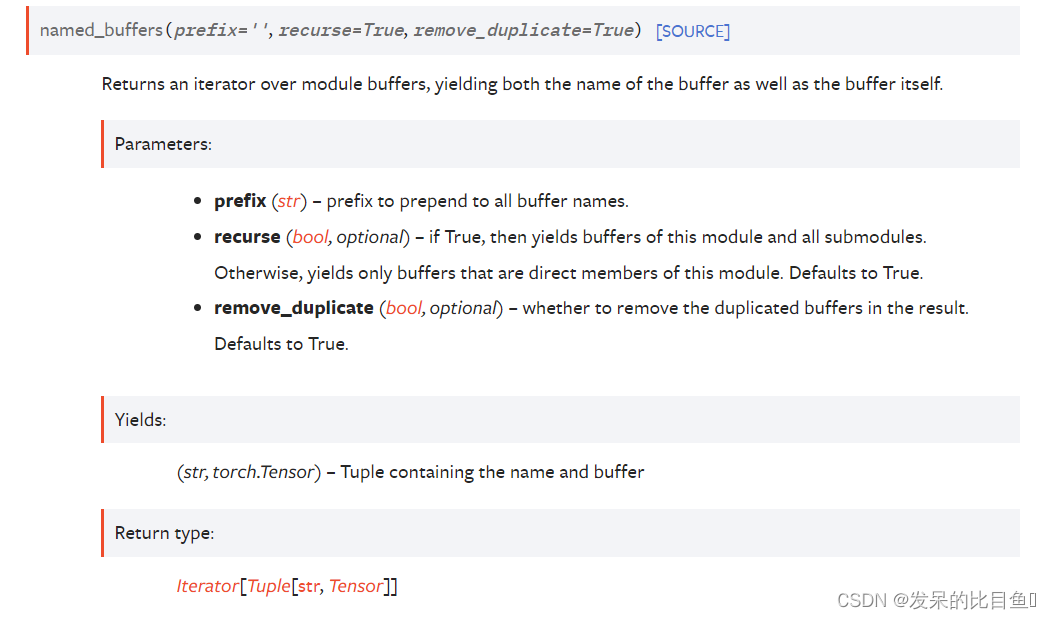
named_buffers(prefix=‘’, recurse=True, remove_duplicate=True)
返回模块缓冲区上的迭代器,产生缓冲区的名称以及缓冲区本身。
>>> for name, buf in self.named_buffers():
>>> if name in ['running_var']:
>>> print(buf.size())
named_children()
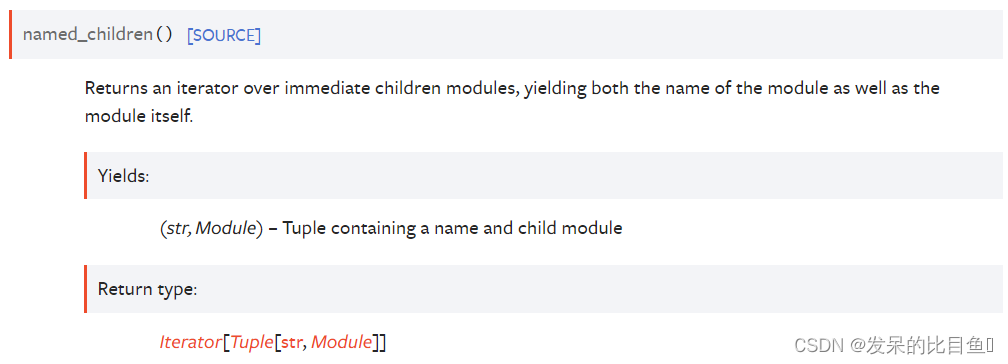
>>> for name, module in model.named_children():
>>> if name in ['conv4', 'conv5']:
>>> print(module)
named_modules(memo=None, prefix=‘’, remove_duplicate=True)
在网络中的所有模块上返回迭代器,生成模块的名称和模块本身。
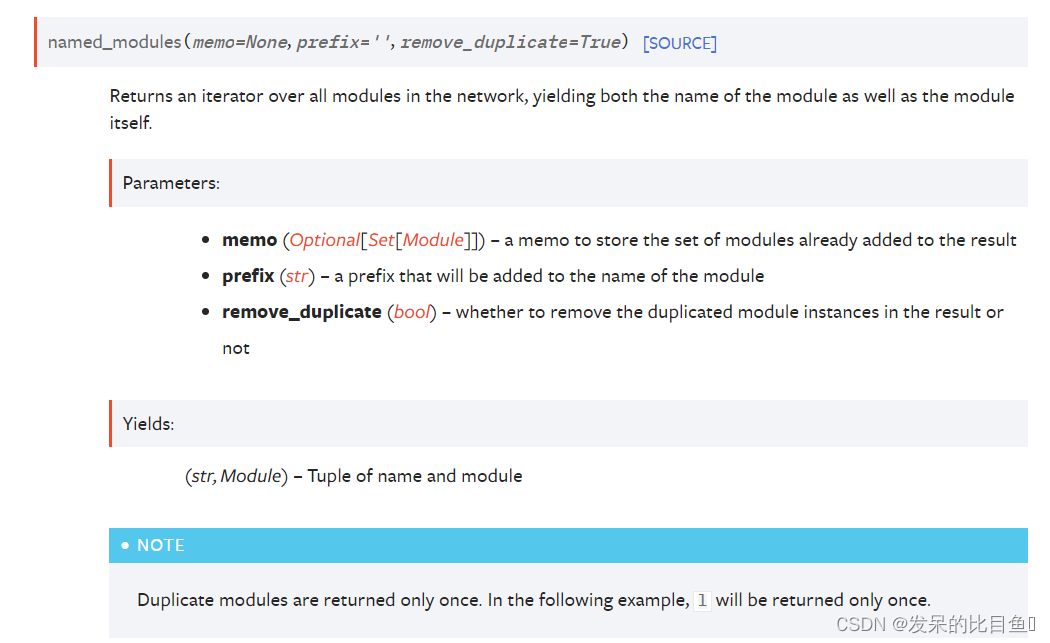
>>> l = nn.Linear(2, 2)
>>> net = nn.Sequential(l, l)
>>> for idx, m in enumerate(net.named_modules()):
... print(idx, '->', m)0 -> ('', Sequential((0): Linear(in_features=2, out_features=2, bias=True)(1): Linear(in_features=2, out_features=2, bias=True)
))
1 -> ('0', Linear(in_features=2, out_features=2, bias=True))
named_parameters(prefix=‘’, recurse=True, remove_duplicate=True)
返回模块参数的迭代器。
这通常传递给优化器。
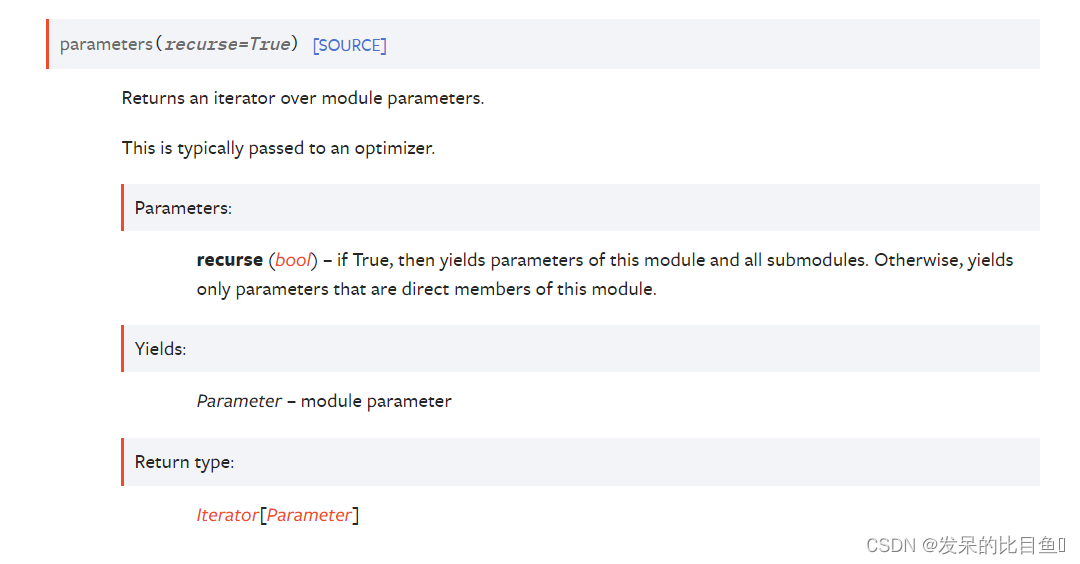
>>> for param in model.parameters():
>>> print(type(param), param.size())
(20L,)
(20L, 1L, 5L, 5L)
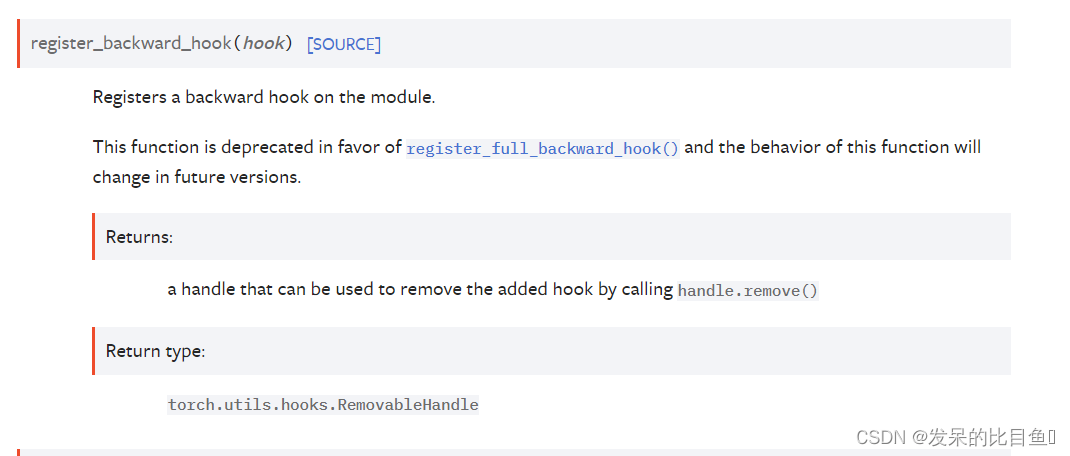
register_backward_hook(hook)
在模块上注册一个后向挂钩。
此函数已弃用,取而代之的是 register_full_backward_hook() 并且此函数的行为将在未来版本中发生变化。
register_forward_hook(hook_fuc)中的hook_fuc函数需要有三个hook_func(model, input, output)这里的input和output是比较好理解的,因为是前向传播,所以input就是输入网络层的输入,output就是该层网络的输出。(注意,hook_func是在该层网络前向传播完成以后执行)
import torch
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as Fdef backward_hook(module, grad_input, grad_output):# 分析: grad_output 是loss相对于out的梯度# 分析: grad_input 是loss分别相对于(2*x)整体和(3*y)整体的梯度,# 因此两者相等print("以下是Grad Input:")print(grad_input)print("以下是Grad Output:")print(grad_output)print("以下是修改后的Grad Input:")new_grad_input_0 = grad_input[0] + 1000.0 #+ 1000.0new_grad_input_1 = grad_input[1] - 2000.0 #- 2000.0new_grad_input = (new_grad_input_0, new_grad_input_1)print(new_grad_input)return new_grad_inputclass Model4cxq(nn.Module):def __init__(self):super(Model4cxq,self).__init__()self.register_backward_hook(backward_hook)def forward(self,x,y):# 实际上是 (2*x) + (3*y) # 当作两个张量相加# 注意这里返回的梯度只有两项,分别相对于(2*x)整体和(3*y)整体的梯度 # 如果需要分别相对于x和y的梯度,必须在张量上添加钩子函数return 2*x + 3*y # 实际上是: return (2*x) + (3*y) 即两个张量相加操作 x = torch.tensor([2.0, 3.0],requires_grad=True)
y = torch.tensor([6.0, 4.0],requires_grad=True)criterion = nn.MSELoss()
model = Model4cxq()
out = model(x,y)
target = torch.tensor([14.0, 12.0],requires_grad=True)
loss = criterion(out, target)
print('loss =',loss)
loss.backward()
print('backward()结束'.center(50,'-'))
print('out.grad:',out.grad)
print('x.grad:',x.grad)
print('y.grad:',y.grad)
print('target.grad:',target.grad)
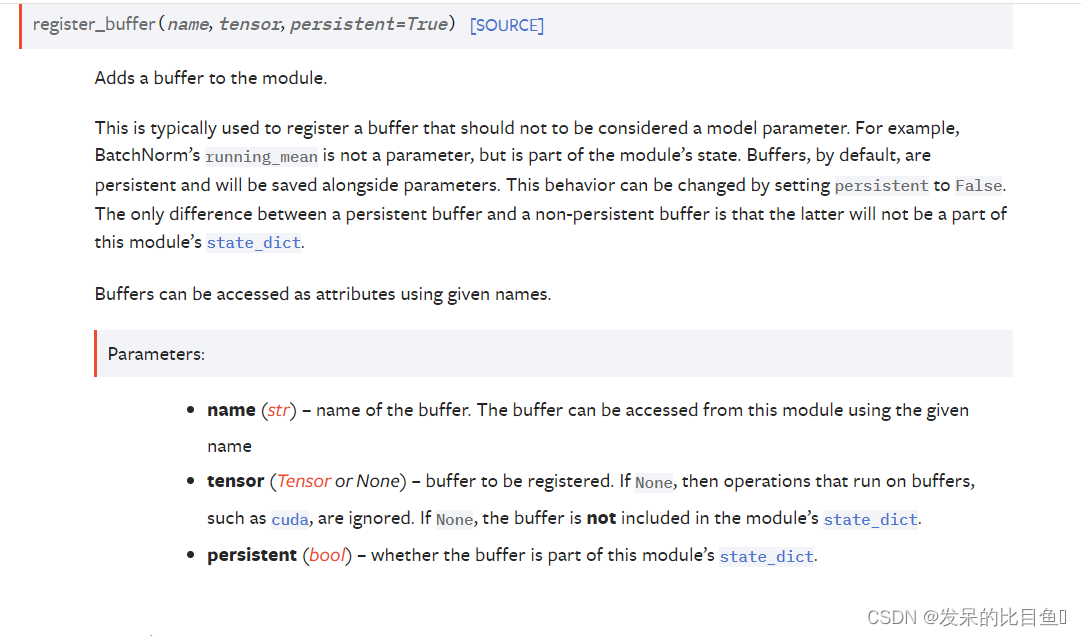
register_buffer(name, tensor, persistent=True)
向模块添加缓冲区。
这通常用于注册不应被视为模型参数的缓冲区。 例如,BatchNorm 的 running_mean 不是参数,而是模块状态的一部分。 默认情况下,缓冲区是持久的,并将与参数一起保存。 可以通过将 persistent 设置为 False 来更改此行为。 持久缓冲区和非持久缓冲区之间的唯一区别是后者不会成为该模块的 state_dict 的一部分。
可以使用给定的名称将缓冲区作为属性进行访问。
>>> self.register_buffer('running_mean', torch.zeros(num_features))
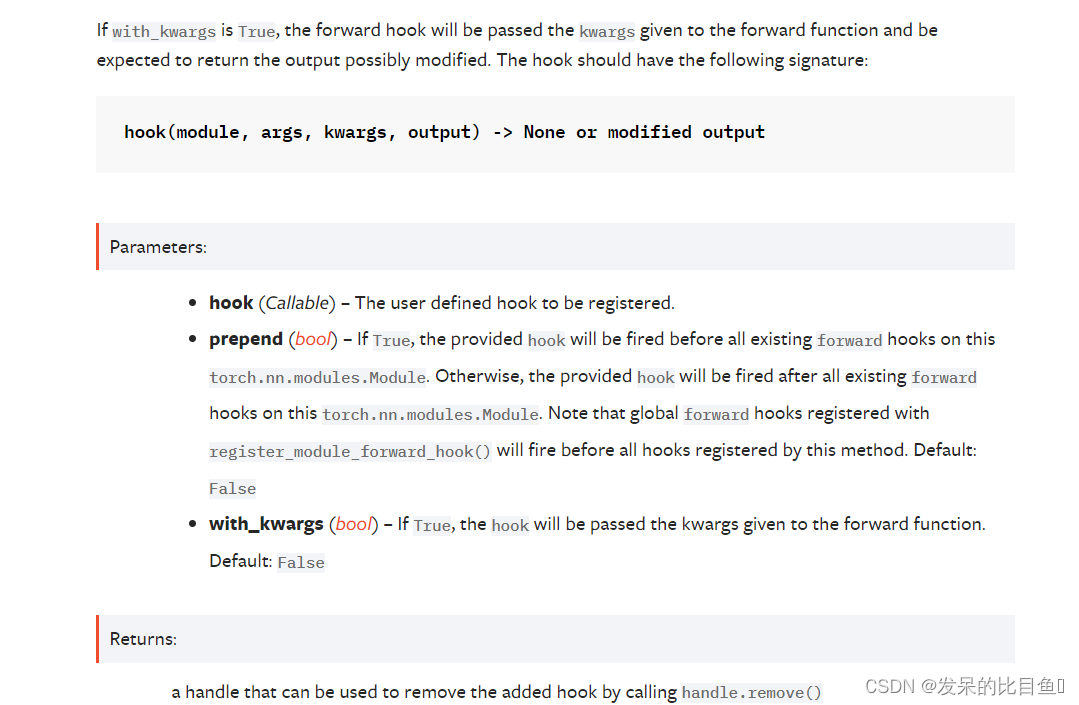
*register_forward_hook(hook, , prepend=False, with_kwargs=False)
在模块上注册一个前向挂钩。
每次 forward() 计算出输出后,都会调用该挂钩。
如果 with_kwargs 为 False 或未指定,则输入仅包含提供给模块的位置参数。 关键字参数不会传递给 hooks 而只会传递给 forward。 钩子可以修改输出。 它可以就地修改输入,但不会对转发产生影响,因为这是在调用 forward() 之后调用的。 挂钩应具有以下签名:
import torch
net1 = nn.Linear(4,2)
net2 = nn.Linear(2,1)def hook_func(model, input, output):print("model:", model)print("input", input)print("output", output)x=torch.tensor([[1.,2.,3.,4.]], requires_grad= True)haddle1 = net1.register_forward_hook(hook_func)y = net1(x)
print(y)
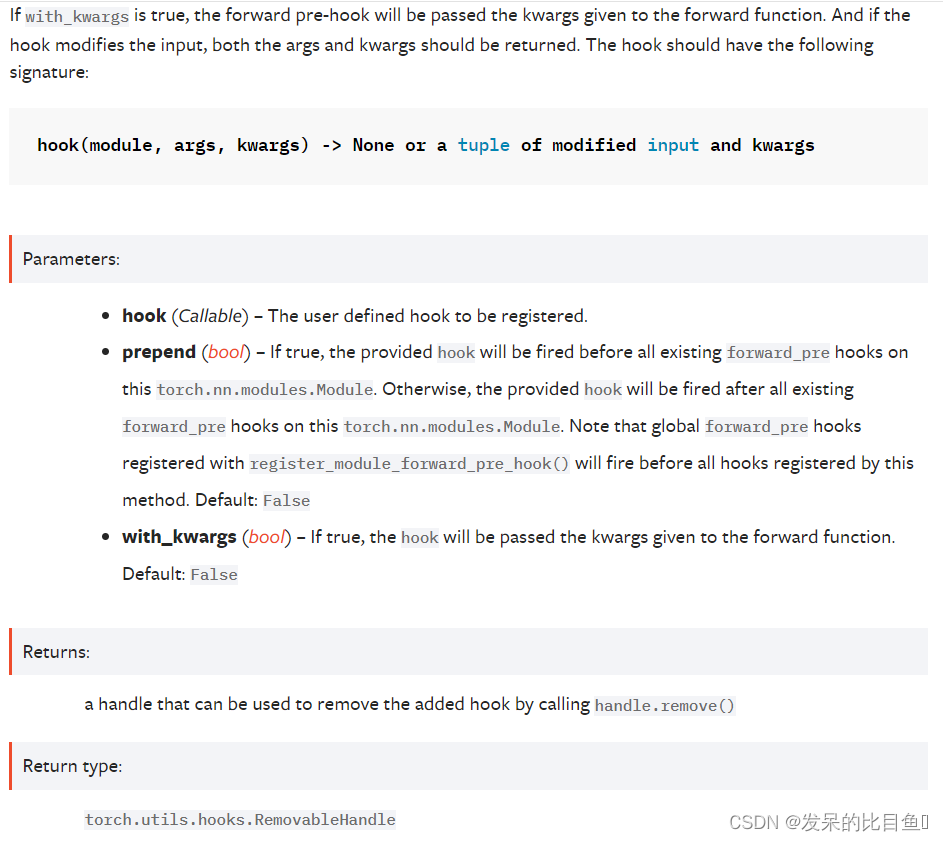
*register_forward_pre_hook(hook, , prepend=False, with_kwargs=False)
在模块上注册前向预挂机。
每次调用 forward() 之前都会调用该钩子。
如果 with_kwargs 为 false 或未指定,则输入仅包含提供给模块的位置参数。 关键字参数不会传递给 hooks 而只会传递给 forward。 钩子可以修改输入。 用户可以在挂钩中返回元组或单个修改后的值。 如果返回单个值,我们会将值包装到一个元组中(除非该值已经是一个元组)。 挂钩应具有以下签名:
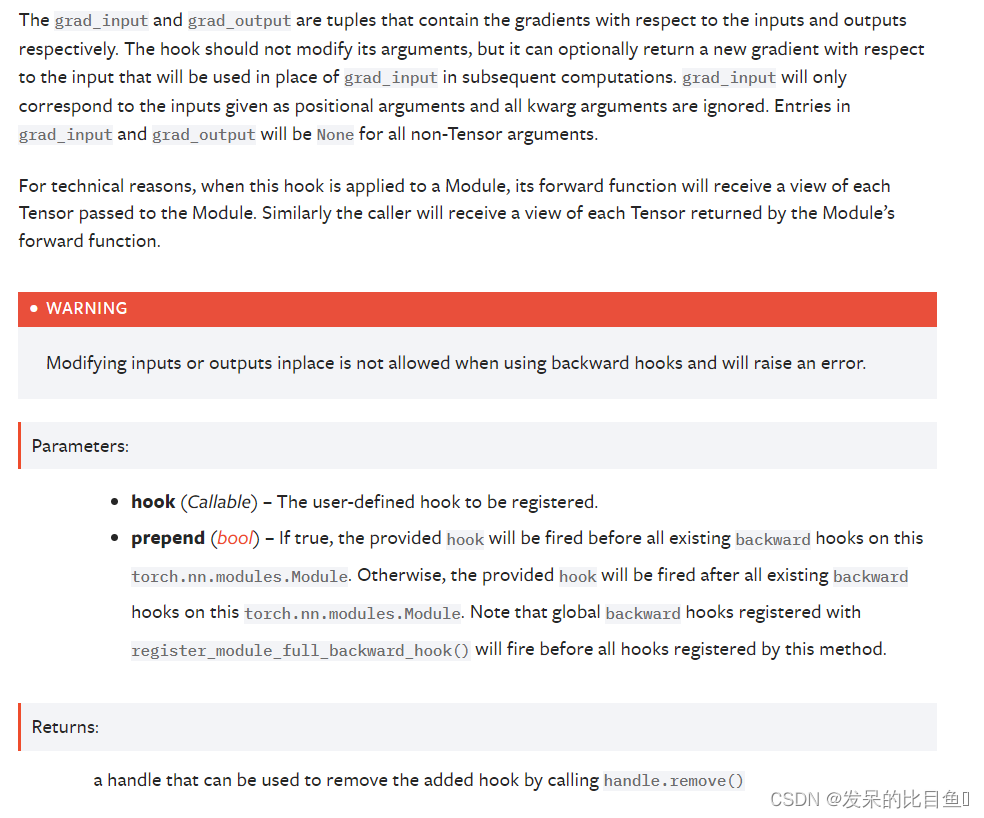
register_full_backward_hook(hook, prepend=False)
在模块上注册一个后向挂钩。
每次计算模块的梯度时都会调用挂钩,即当且仅当计算模块输出的梯度时挂钩才会执行。 挂钩应具有以下签名:
register_full_backward_pre_hook(hook, prepend=False)
在模块上注册一个反向预挂钩。
每次计算模块的梯度时都会调用该钩子。 挂钩应具有以下签名:
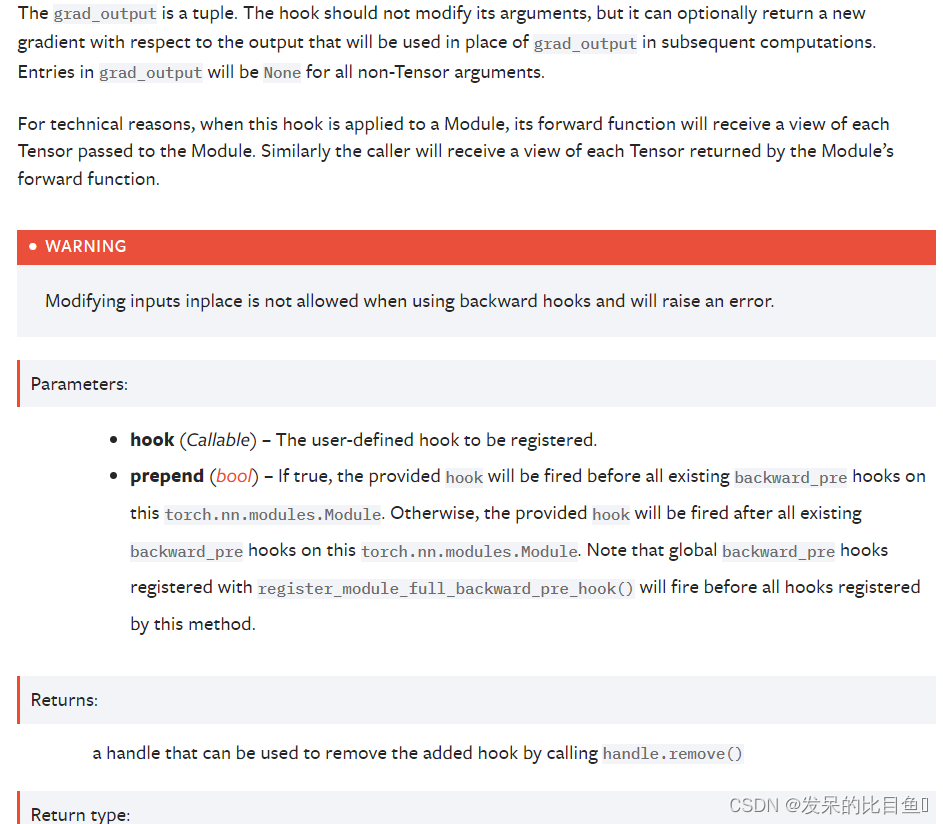
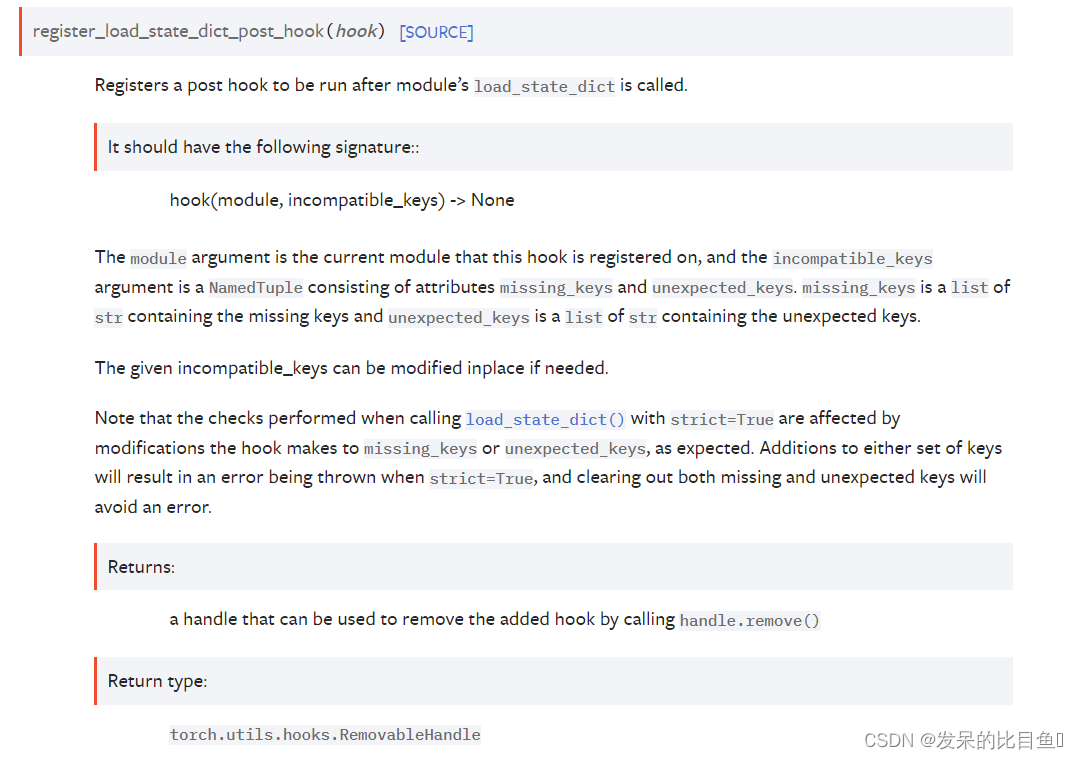
register_load_state_dict_post_hook(hook)
在模块上注册一个反向预挂钩。
每次计算模块的梯度时都会调用该钩子。 挂钩应具有以下签名:
register_module(name, module)
add_module() 的别名。
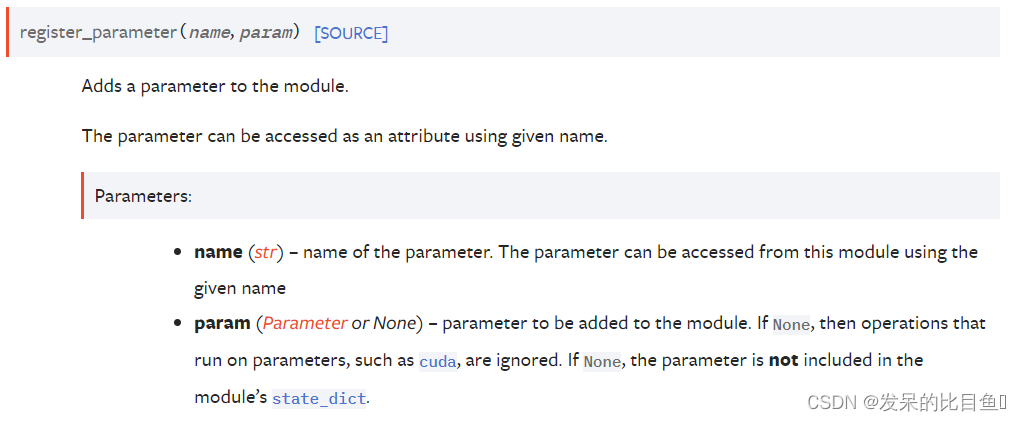
register_parameter(name, param)
向模块添加参数。
可以使用给定名称将参数作为属性访问
register_state_dict_pre_hook(hook)
这些钩子将在调用 state_dict 之前使用参数调用:self、prefix 和 keep_vars。 已注册的钩子可用于在调用 state_dict 之前执行预处理

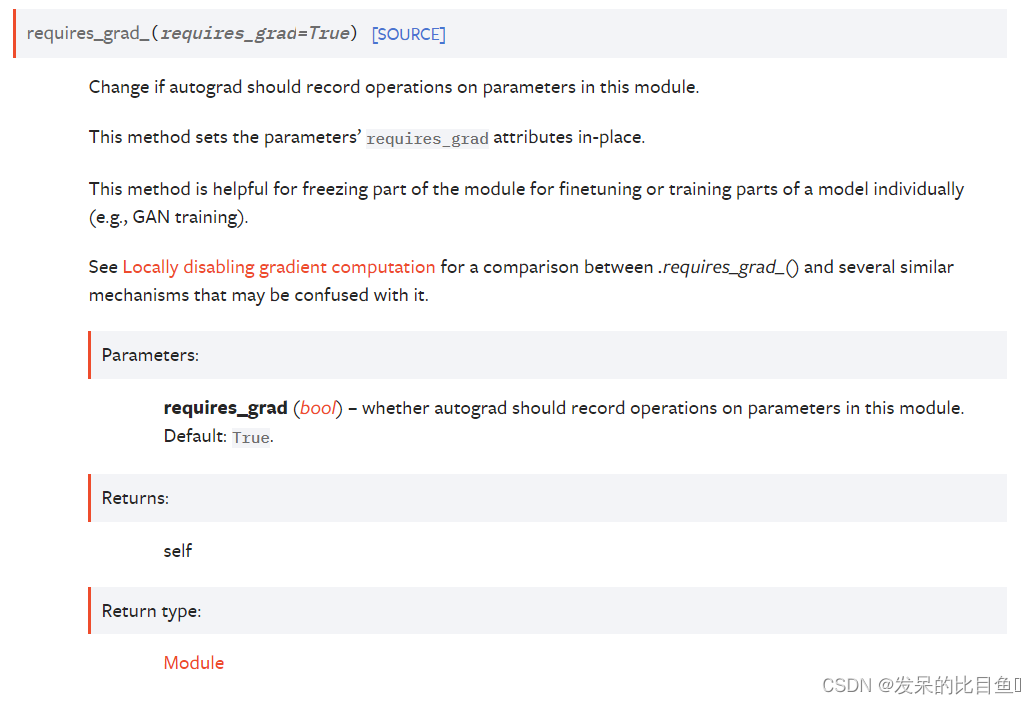
requires_grad_(requires_grad=True)
更改 autograd 是否应记录对该模块中参数的操作。
此方法就地设置参数的 requires_grad 属性。
此方法有助于冻结部分模块以单独微调或训练模型的部分(例如,GAN 训练)。
请参阅 Locally disabling gradient computation 以比较 .requires_grad_() 和可能与其混淆的几种类似机制。
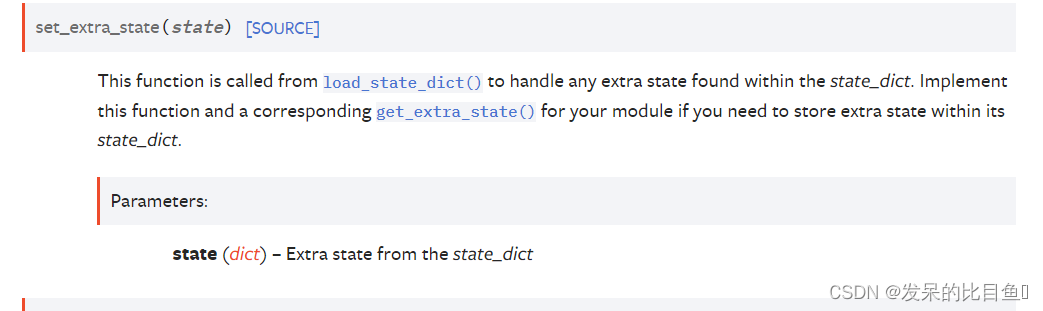
set_extra_state(state)
从 load_state_dict() 调用此函数以处理在 state_dict 中找到的任何额外状态。 如果您需要在其 state_dict 中存储额外状态,请为您的模块实现此函数和相应的 get_extra_state()。
share_memory()
see torch.Tensor.share_memory_()

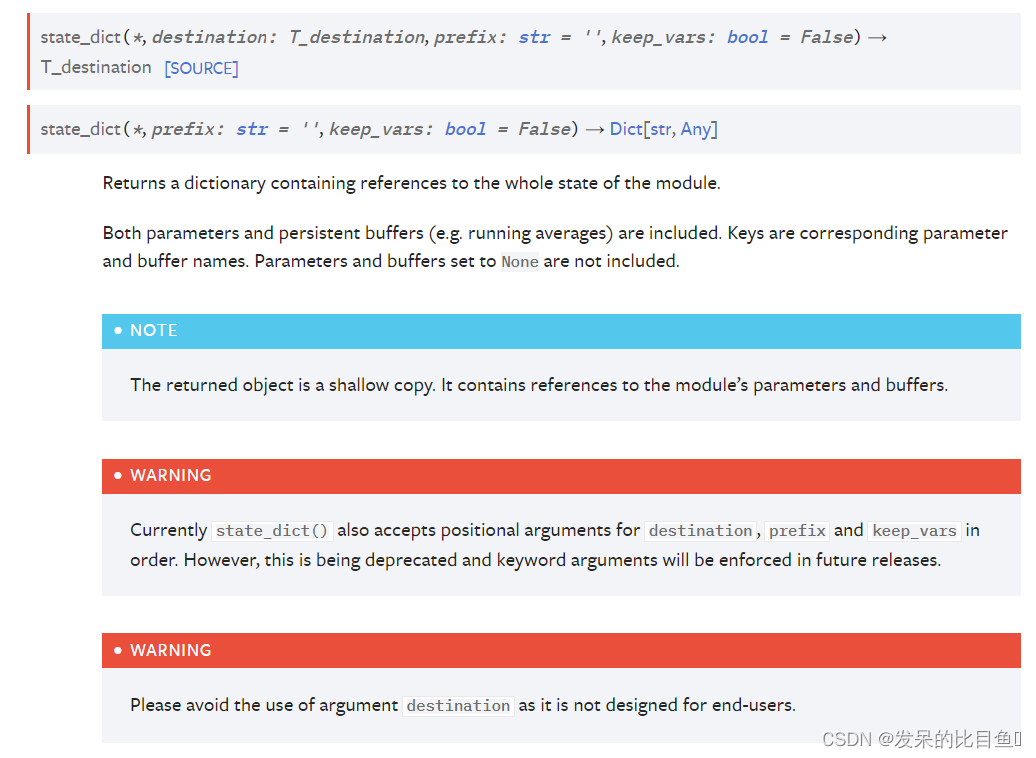
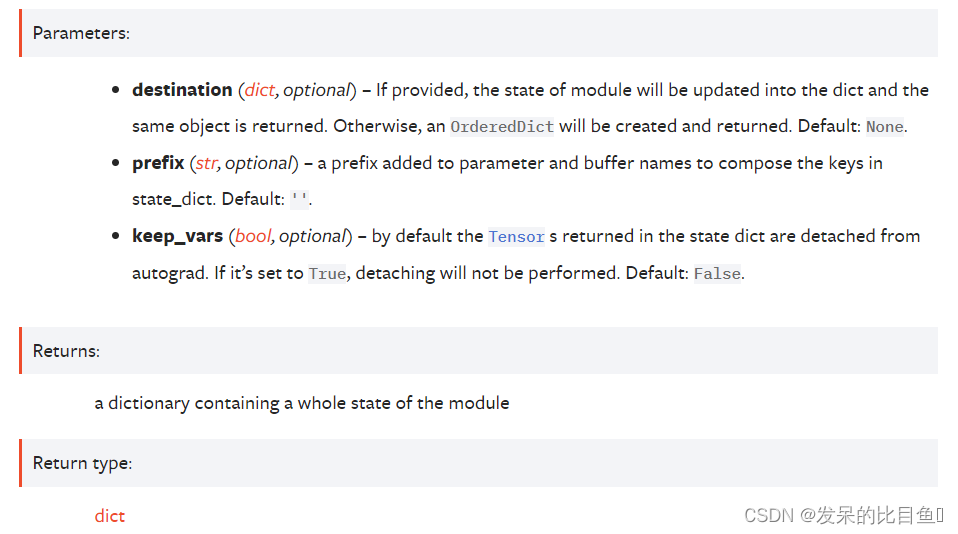
state_dict(*, prefix: str = ‘’, keep_vars: bool = False) → Dict[str, Any]
返回包含对模块整个状态的引用的字典。
包括参数和持久缓冲区(例如运行平均值)。 键是相应的参数和缓冲区名称。 不包括设置为 None 的参数和缓冲区。
>>> module.state_dict().keys()
['bias', 'weight']
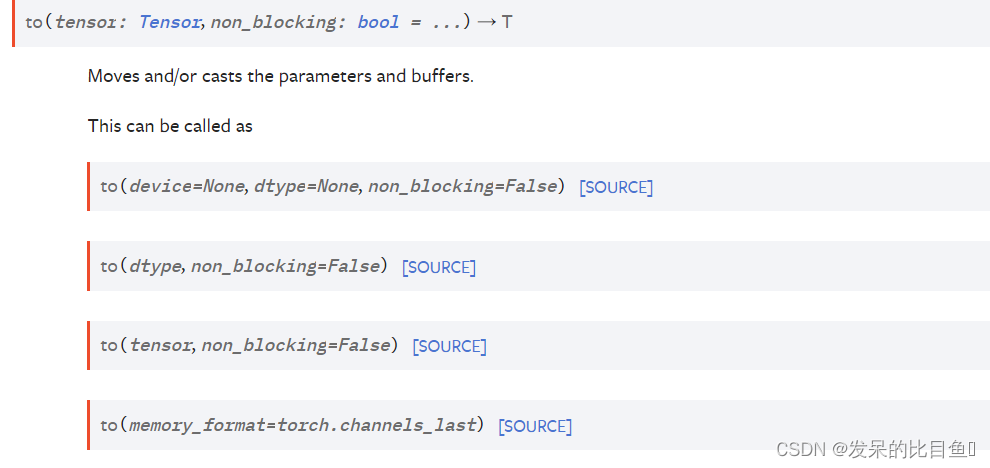
to(device: Optional[Union[int, device]] = …, dtype: Optional[Union[dtype, str]] = …, non_blocking: bool = …) → T
>>> linear = nn.Linear(2, 2)
>>> linear.weight
Parameter containing:
tensor([[ 0.1913, -0.3420],[-0.5113, -0.2325]])
>>> linear.to(torch.double)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1913, -0.3420],[-0.5113, -0.2325]], dtype=torch.float64)
>>> gpu1 = torch.device("cuda:1")
>>> linear.to(gpu1, dtype=torch.half, non_blocking=True)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1914, -0.3420],[-0.5112, -0.2324]], dtype=torch.float16, device='cuda:1')
>>> cpu = torch.device("cpu")
>>> linear.to(cpu)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1914, -0.3420],[-0.5112, -0.2324]], dtype=torch.float16)>>> linear = nn.Linear(2, 2, bias=None).to(torch.cdouble)
>>> linear.weight
Parameter containing:
tensor([[ 0.3741+0.j, 0.2382+0.j],[ 0.5593+0.j, -0.4443+0.j]], dtype=torch.complex128)
>>> linear(torch.ones(3, 2, dtype=torch.cdouble))
tensor([[0.6122+0.j, 0.1150+0.j],[0.6122+0.j, 0.1150+0.j],[0.6122+0.j, 0.1150+0.j]], dtype=torch.complex128)
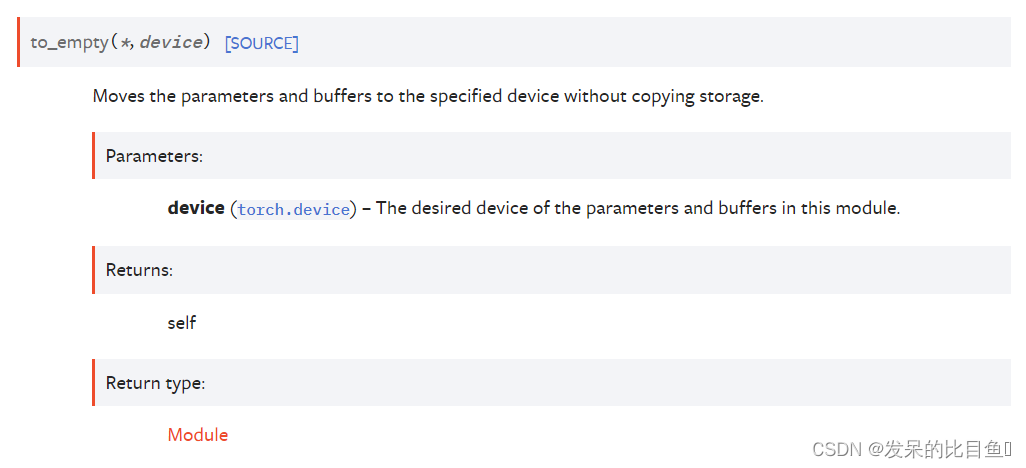
to_empty(*, device)
将参数和缓冲区移动到指定设备而不复制存储。
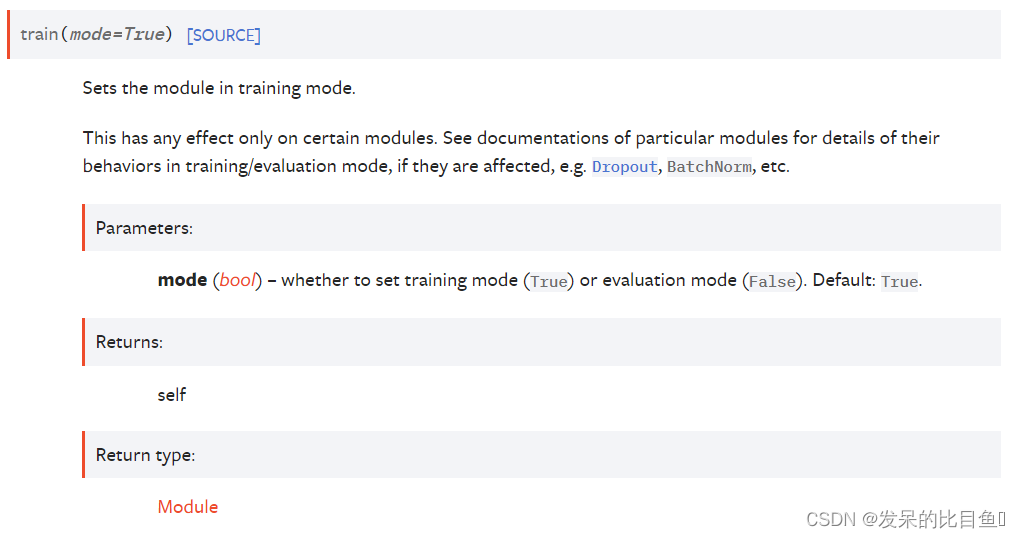
train(mode=True)
将模块设置为训练模式。
这仅对某些模块有任何影响。 如果它们受到影响,请参阅特定模块的文档以了解它们在训练/评估模式下的行为的详细信息,例如 Dropout、BatchNorm 等
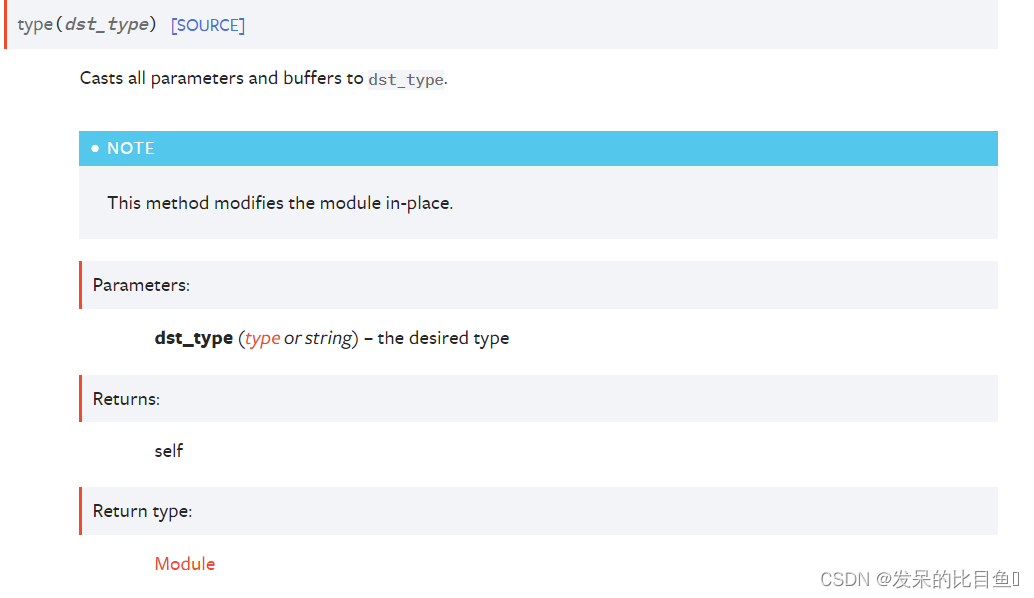
type(dst_type)
将所有参数和缓冲区转换为dst_type。
xpu(device=None)
将所有模型参数和缓冲区移动到 XPU。
这也使关联参数和缓冲区成为不同的对象。 因此,如果模块在优化时将驻留在 XPU 上,则应在构建优化器之前调用它。
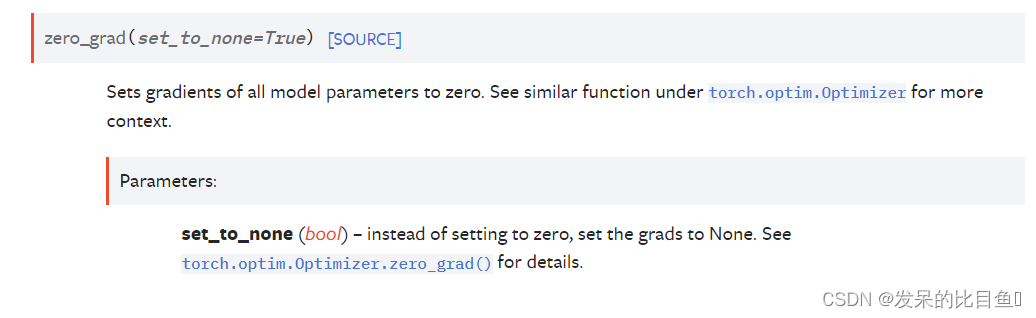
zero_grad(set_to_none=True)