IO流之计算机存储规则
创始人
2025-06-01 09:41:37
引言:
字节流可以读写所有文件,字符流只可以读写纯文本文件
1、计算机的存储规则

八个比特为组成一个字节,字节是计算机中最小的存储单位
1.1、字符集
每一个二进制数字,对应码表中的一个英文字符,中文字符,符号等
ASCII:英文(0-127)
GBK:英文➕中文(GB国标 K拓展)
BIG5:台湾文字用
UniCode:英文➕中文(万国码)
1.2、存取规则 (英文)

想要存储在计算机里,必须是八的倍数,所以对于不足8位的二进制数字,计算机会进行补码操作。
存储:在ASCII查询存储英文对应的十进制数字,将其转化做二进制数字,对其进行编码,再存储。
读取:对其进行解码,随后将二进制数字转化做十进制数,在ASCII码表中查询,再获得。
特点:英文一个字节存储,字符集都兼容ASCII码表,开头以0补码,转换成十进制一定是一个正数。
ASCII码表:
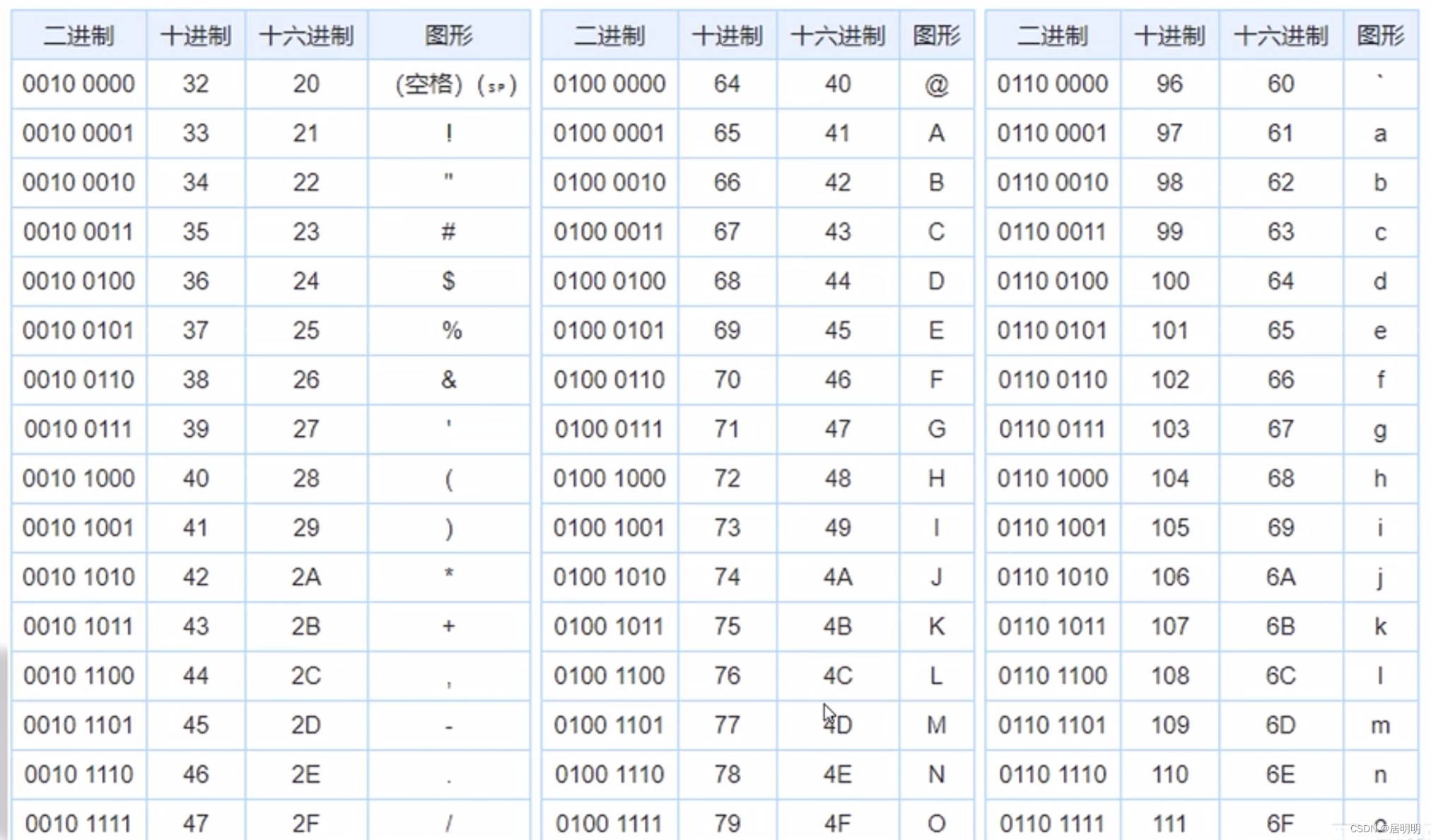
1.3、存取规则(中文)

与英文类似,在GBK字符集,或者Unicode字符集进行查询,随后将其编码。
为了与英文区分,同时因为汉字数量很多,有以下特点:
1、汉字在字符集中对应的数字都是两个字节。
2、汉字的第一个字节(也称之为高位字节),一定是以1开头,转换成十进制后是一个负数。
3、汉字的第二个字节(也称之为低位字节),可以是1/0开头,转换过后可正可负。

1.4、Unicode解码方式
UTF-16:2-4个字节(英文2个)
UTF-32:4个字节
UTF-8 :1-4个字节(英文1个,中文三个)
补码:
英文:开头0
中文:1110 10 10

小tips
UTF-8是一个字符集吗?
答:不是,UTF-8是Unicode字符集的一种编码方式
一种字符集只能对应一种编码方式吗?
答:不是,Unicode有多种编码方式
1.5、乱码现象
为什么会有乱码?
原因1:
字节流读取文件时,按照一个字节一个字节的读取,在UTF-8编码方式中,中文为3个字节,读取时拆分来读,会出现乱码现象。

字节流读取按照一个字节一个字节的读取,在ASCII码表中查询,一个字节查询完毕打印一个字节,因此中文会乱码。
原因2:
编码时和解码时采取的方式不统一。

注:GBK编码方式中文占据两个字节


1.6拓展:为什么字节流拷贝不会出现乱码呢?
用字节流读取时,按照一个字节一个字节的读取,在ASCII码表中查询,一个字节查询完毕打印一个字节,因此中文会乱码。
一个字节一个字节的拷贝,数据没有丢失
用文件打开时,如果打开时编码表、编码方式和数据源一致,不会出现乱码。
上一篇:MySQL学习技巧
相关内容
热门资讯
谁能低估日拱一卒的公司呢? 谁...
题图|视觉中国滴滴于6月5日晚交出了2025年一季度业绩报告。一季度,滴滴核心平台(涵盖中国出行与国...
V观财报|ST路通未及时披露重...
中新经纬6月8日电 无锡路通视信网络股份有限公司(下称ST路通或公司)8日晚公告,公司及相关...
大连多名游客隔铁网薅虎毛!宣称...
本文转自【锦观新闻】; 近日,辽宁大连,狮虎园有游客隔着铁网偷拽老虎毛,说是镇宅避邪,引发热议。 视...
深企投助力江苏灌云经济开发区对...
2025年4月24日,深企投助力江苏灌云经济开发区副主任赵玺一行对接2家优强企业,洽谈智能机器人项目...
两年前没卖房,现在亏了30万,...
在目前宁波的房产市场,对于没有买卖打算的朋友来说,基本都是通过一些数字变化来感知涨落。 不过最近,东...
港股次新股狂欢:17只翻倍牛股...
港股自去年9月以来流动性和估值持续改善,伴随着主要指数震荡上行,创新药、新消费走出结构性牛市行情,其...
周末刷屏!“反内卷、恶性竞争”...
红星资本局6月8日消息,6月6日-6月7日,2025中国汽车重庆论坛在重庆举行,“反内卷”“抵制恶性...
刘强东正在“复制”一个携程
文 | 摩根商研所 携程最近好像摊上事了。 倒不是说携程自己运营遇到什么情况,而是京东可能要直击携...
亚马逊突袭:电池含量商品大规模...
2025年5月20日起,亚马逊美国站展开了大规模的商品下架行动,尤其是针对含有纽扣电池、锂电池的电子...
恭喜!张镇麟举办婚礼 郭士强和...
6月8日消息,张镇麟在丽江悦榕庄酒店举办婚礼 。 中国男篮主教练郭士强、广州男篮球员郭艾伦均出席了张...
薇娅被曝隐秘“复出”!小程序出...
红星资本局6月8日消息,近日,淡出直播行业许久的薇娅又有了“复出”的迹象。有网友在社交平台发文称,一...
港股新消费指数年内涨幅超20%...
如果说今年什么最火,那一定是新消费公司。泡泡玛特已经变成“年轻人的茅台”,老铺黄金、蜜雪冰城、毛戈平...
IPO周报:新增受理3单上市申...
6月3日~6月8日当周(下同),沪深北交易所新增受理3单IPO申请,1家过会,2家提交注册,1家注册...
头部公募发力牌照“全产业链”,...
在高度依赖第三方销售机构的公募行业,在费率下调趋势中告别旱涝保收的基金公司,已将基金销售业务作为失之...
北交所将进入“双指数”运行阶段...
开市三年零七个月后,年轻的北交所即将迎来“双指数”运行的新时代。6月6日晚,北交所公告显示,北京证券...
金观平:持续完善促消费长效机制
本文转自【中国经济网-《经济日报》】; 今年以来,扩内需促消费政策密集出台,消费品以旧换新加力扩围,...
机构论后市丨预计指数整体维持震...
沪指本周累计涨1.13%,深成指累计涨1.42%,创业板指累计涨2.32%。A股后市怎么走?看看机构...
荣耀的“精神三变”:从负重骆驼...
作 者:微澜来 源:正和岛(ID:zhenghedao)荣耀的叙事逻辑变了。在看完5月28日,荣耀C...
V观财报|恒润股份总经理周洪亮...
中新经纬6月8日电 恒润股份8日公告,董事兼总经理周洪亮等合计拟减持不超公司总股本1.89%...
立案,终止上市!又一“老油企”...
又一家上市公司将告别A股! 6月6日,*ST海越(600387)收到上海证券交易所《关于海越能源集团...
宇树背后的租赁人,一单赚2万 ...
出品 | 虎嗅科技组作者 | 房晓楠编辑 | 苗正卿头图 | 视觉中国一场超出预期的春晚舞台表演、一...
罕见一幕发生,银行存款利率跌破...
作者|碎叶冬青近日罕见一幕发生,我们又一次见证了历史。5月20日,六大行宣布下调人民币存款利率,最大...
三大猪企5月生猪销量销售收入环...
三大上市猪企牧原股份(002714.SZ)、新希望(000876.SZ)、温氏股份(300498.S...
合资车复苏战,始于脱下长衫!5...
合资车的长衫“长衫”一词,从中小学课文《孔乙己》开始,就被赋予了特殊的含义。它既是过去荣誉的象征,也...
新高!债券ETF,总规模突破3...
截至6月6日,债券ETF的总管理规模首次突破3000亿元,再创历史新高。 数据显示,截至6月6日,债...
比亚迪回应“常压油箱”及“车圈...
红星资本局6月8日消息,今日,比亚迪(002594.SZ)集团品牌及公关处总经理李云飞发文回应“常压...
投后期又香了 投后期又香了 投...
投资后期的资金开始活跃了。一切从港股IPO火热说起。2025年以来,香港新股集资额超过760亿港元,...
从26亿美元出海神话到债务泥潭...
还有机会“上岸”吗?现金流紧张的荣昌生物终于又融到了钱。近期港股市场创新药板块人气回暖,港股通创新药...
高瑞东:非农数据高于预期,美联...
高瑞东 周欣平(高瑞东 系光大证券首席经济学家、中国首席经济学家论坛理事)核心观点事件:2025年6...
熊园:美国经济将迎来至关重要的...
熊园 刘新宇(熊园 系国盛证券首席经济学家、中国首席经济学家论坛理事)事件:北京时间6月6日20:3...