linux系统性能分析(一)
linux系统性能分析
- 1 影响 Linux 性能的各种因素
- 1.1 系统硬件资源
- 1. CPU
- 2. 内存
- 3. 磁盘 IO
- 4. 网络带宽
- 1.2 操作系统相关资源
- 1. 系统安装优化
- 2. 内核参数优化
- 3. 文件系统优化
- 1.3 程序问题
- 2 Linux 性能优化工具
- 2.1 CPU 性能评估工具
- 1. vmstat(系统默认自带)
- 2. iostat(需要安装 sysstat 工具包)
- 3. uptime
- 4. top
- 2.2 内存性能评估
- 1. free
- 2. sar/pidstat
- 2.3 磁盘性能评估
- 1. iostat
- 2. pidstat (如上)
- 3. sar(如上)
- 2.4 网络性能评估
- 1. ping
- 2. netstat
- 3. mtr/traceroute 命令
- 3. 系统性能分析标准
1 影响 Linux 性能的各种因素
1.1 系统硬件资源
1. CPU
判断多核 CPU 与超线程
-
查询体系CPU的物理个数:
[root@dbc-server-554 zabbix]# cat /proc/cpuinfo |grep "physical id"|sort |uniq|wc -l 1一般电脑或者笔记本的主板只有一个CPU槽只能安装一个CPU,但服务器就不一样了一般服务器都会有双CPU槽的可以安装两个CPU的。但超级计算机就不一样了他们的CPU根据性能会拥有多个CPU,例如漂亮国的超级计算机Blue Gene/L拥有32000颗CPU的
-
查询体系具有CPU的逻辑核数:
[root@dbc-server-554 zabbix]# cat /proc/cpuinfo | grep "processor" | wc -l 8 -
查询体系CPU的物理核数:
[root@dbc-server-554 zabbix]# cat /proc/cpuinfo | grep "cpu cores" | uniq cpu cores : 4 -
查询体系CPU是否启用超线程:
[root@dbc-server-554 zabbix]# cat /proc/cpuinfo | grep -e "cpu cores" -e "siblings" | sort | uniq cpu cores : 4 siblings : 8若是cpu cores数量和siblings数量一致,则没有启用超线程,不然超线程被启用。
”超线程(Hyper-Threading,简称“HT”)”技术。超线程技术就是利用特殊的硬件指令,把两个逻辑内核模拟成两个物理芯片,让单个处理器都能使用线程级并行计算,进而兼容多线程操作系统和软件,减少了CPU的闲置时间,提高的CPU的运行效率。超线程技术是在一颗CPU同时执行多个程序而共同分享一颗CPU内的资源,理论上要像两颗CPU一样在同一时间执行两个线程,虽然采用超线程技术能同时执行两个线程,但它并不象两个真正的CPU那样,每个CPU都具有独立的资源。当两个线程都同时需要某一个资源时,其中一个要暂时停止,并让出资源,直到这些资源闲置后才能继续。因此超线程的性能并不等于两颗CPU的性能。 -
查看逻辑CPU、CPU型号:
[root@dbc-server-554 zabbix]# cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c8 Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz -
查看CPU实时主频
[root@dbc-server-554 zabbix]# cat /proc/cpuinfo |grep MHz|uniq cpu MHz : 3426.635 cpu MHz : 3600.000 cpu MHz : 3601.098 cpu MHz : 3590.112 cpu MHz : 3310.400 cpu MHz : 2602.441 cpu MHz : 2685.937 cpu MHz : 2438.525 -
是否支持64位计算
[root@dbc-server-554 zabbix]# cat /proc/cpuinfo | grep flags | grep ' lm ' | wc -l 8结果大于0, 说明支持64bit计算. lm指long mode, 支持lm则是64bit
标识:
processor 条目包括这一逻辑处理器的唯一标识符。
physical id 条目包括每个物理封装的唯一标识符。
core id 条目保存每个内核的唯一标识符。
siblings 条目列出了位于相同物理封装中的逻辑处理器的数量。
cpu cores 条目包含位于相同物理封装中的内核数量。
如果处理器为英特尔处理器,则 vendor id 条目中的字符串是 GenuineIntel
消耗 CPU 的业务:动态 web 服务、mail 服务
2. 内存
- 物理内存与 swap 的取舍
- 选择 64 位 Linux 操作系统
消耗内存的业务:内存数据库(redis/hbase/mongodb)
3. 磁盘 IO
- RAID 技术(RAID0/1/5/01/10)
- SSD 磁盘
消耗磁盘的业务:数据库服务器
4. 网络带宽
- 网卡/交换机的选择
- 操作系统双网卡绑定
消耗带宽的业务:hadoop 平台、视频业务平台
1.2 操作系统相关资源
1. 系统安装优化
磁盘分区、RAID 设置、swap 设置
2. 内核参数优化
- ulimit -n(最大打开文件数)
- ulimit -u(最大用户数)
3. 文件系统优化
- ext2:Linux 下标准文件系统,无日志记录(inode)功能。
- ext3:在ext2 基础上增加了日志记录功能(inode),仅支持 32000 个子目录。
- ex4:ext3 的后续版本,Linux2.6.28 内核开始支持。无限子目录支持,快速 fsck。
- xfs:高性能文件系统,Linux3.10 内核开始默认支持。
建议:
读操作频繁,同时小文件众多的应用:首选 ext4 文件系统,接下来依次是 xfs、ext3
写操作频繁的应用,首选是 xfs,接下来依次是 ext4 和 ext3
对性能要求不高、数据安全要求不高的业务,ext3 是比较好的选择。
1.3 程序问题
此类问题需要开发人员查看代码,介入处理。但作为运维人员需要给出程序问题的有力证据。
2 Linux 性能优化工具
2.1 CPU 性能评估工具
1. vmstat(系统默认自带)
利用 vmstat 命令可以对操作系统的内存信息、进程状态、CPU活动等进行监视。
常用方式:vmstat 2 3
表示每 2 秒更新一次输出信息,统计 3 次后停止输出。
[root@node1 ~]# vmstat 2 3
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----r b swpd free buff cache si so bi bo in cs us sy id wa st2 0 0 104812 2172 1126668 0 0 1 1 42 16 0 0 100 0 00 0 0 104812 2172 1126672 0 0 0 0 89 141 0 0 100 0 00 0 0 104844 2172 1126672 0 0 0 0 86 136 0 0 100 0 0
对上面每项的输出解释如下:
procs
r列表示运行和等待 cpu 时间片的进程数, 这个值如果长期大于系统CPU 的个数,说明CPU 不足,需要增加 CPU。- b 列表示在等待资源的进程数,比如正在等待 I/O、或者内存交换等。
memory
- swpd 列表示切换到内存交换区的内存数量(以 k为单位) 。如果 swpd 的值不为0,或者比较大,只要 si、so 的值长期为 0,这种情况下一般不用担心,不会影响系统性能。
- free列表示当前空闲的物理内存数量(以 k为单位)
- buff 列表示 buffers cache的内存数量,一般对块设备的读写才需要缓冲。
- cache列表示 page cached 的内存数量,一般作为文件系统 cached,频繁访问的文件都会被 cached,如果 cache 值较大,说明 cached 的文件数较多,如果此时
io中 bi比较小,说明文件系统效率比较好。
swap
- si列表示由磁盘调入内存,也就是内存进入内存交换区的数量。
- so 列表示由内存调入磁盘,也就是内存交换区进入内存的数量。
一般情况下, si、 so 的值都为 0, 如果 si、 so 的值长期不为 0, 则表示系统内存不足。需要增加系统内存。
io
显示磁盘读写状况
- bi 列表示从块设备读入数据的总量(即读磁盘) (每秒 kb) 。
- bo 列表示写入到块设备的数据总量(即写磁盘) (每秒 kb)。
这里我们设置的 bi+bo 参考值为 1000,如果超过 1000,而且 wa值较大,则表示系统磁盘 IO 有问题,应该考虑提高磁盘的读写性能。
system
显示采集间隔内发生的中断数
- in 列表示在某一时间间隔中观测到的每秒设备中断数。
- cs 列表示每秒产生的上下文切换次数。
上面这 2 个值越大,会看到由内核消耗的 CPU 时间会越多。
cpu
显示了 CPU 的使用状态,此列是我们关注的重点
us列显示了用户进程消耗的 CPU 时间百分比。us 的值比较高时,说明用户进程消耗的 cpu 时间多,但是如果长期大于50%,就需要考虑优化程序或算法。sy列显示了内核进程消耗的 CPU 时间百分比。sy的值较高时,说明内核消耗的CPU 资源很多。
根据经验, us+sy的参考值为 80%, 如果 us+sy大于 80%说明可能存在 CPU 资源不足。
id列显示了 CPU 处在空闲状态的时间百分比。- wa 列显示了 IO 等待所占用的 CPU 时间百分比。wa 值越高,说明 IO 等待越严重,根据经验,wa 的参考值为
20%,如果 wa 超过 20%,说明 IO 等待严重,引起 IO 等待的原因可能是磁盘大量随机读写造成的, 也可能是磁盘或者磁盘控制器的带宽瓶颈造成的(主要是块操作) 。 - st 从虚拟设备中获得的时间
综上所述, 在对 CPU 的评估中, 需要重点注意的是procs 项 r 列的值和 CPU 项中 us、sy和 id 列的值。
2. iostat(需要安装 sysstat 工具包)
iostat 是 I/O statistics(输入/输出统计)的缩写,主要的功能是对系统的磁盘 I/O 操作进行监视。
常用方式:iostat -c 3 5(表示统计5次,间隔3秒)
其中,-c 表示显示CPU 的使用情况,-d:显示磁盘的使用情况。
[root@node1 ~]# iostat -c 3 5
Linux 3.10.0-1160.76.1.el7.x86_64 (node1) 03/13/2023 _x86_64_ (2 CPU)avg-cpu: %user %nice %system %iowait %steal %idle0.01 0.00 0.06 0.01 0.00 99.92avg-cpu: %user %nice %system %iowait %steal %idle0.00 0.00 0.17 0.00 0.00 99.83avg-cpu: %user %nice %system %iowait %steal %idle0.17 0.00 0.00 0.00 0.00 99.83avg-cpu: %user %nice %system %iowait %steal %idle0.00 0.00 0.00 0.00 0.00 100.00avg-cpu: %user %nice %system %iowait %steal %idle0.00 0.00 0.17 0.00 0.00 99.83统计硬盘使用情况,间隔3秒,统计两次
[root@node1 ~]# iostat -d 3 2
Linux 3.10.0-1160.76.1.el7.x86_64 (node1) 03/13/2023 _x86_64_ (2 CPU)Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
scd0 0.00 0.00 0.00 1028 0
sda 0.12 1.51 0.94 651630 406752
sdb 0.03 0.07 0.86 29875 373273
sdc 0.00 0.01 0.00 6000 0
dm-0 0.16 1.50 1.80 647861 777868
dm-1 0.00 0.00 0.00 2072 0
dm-2 0.00 0.00 0.00 1036 0Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
scd0 0.00 0.00 0.00 0 0
sda 0.00 0.00 0.00 0 0
sdb 0.00 0.00 0.00 0 0
sdc 0.00 0.00 0.00 0 0
dm-0 0.00 0.00 0.00 0 0
dm-1 0.00 0.00 0.00 0 0
dm-2 0.00 0.00 0.00 0 0
3. uptime
uptime 是监控系统性能最常用的一个命令,主要用来统计系统当前的运行状况,输出的信息依次为:系统现在的时间、 系统从上次开机到现在运行了多长时间、 系统目前有多少登陆用户、系统在一分钟内、五分钟内、十五分钟内的平均负载。
[root@node1 ~]# uptime13:12:50 up 5 days, 16 min, 1 user, load average: 0.00, 0.03, 0.05
4. top
参考第二章
2.2 内存性能评估
1. free
free 命令是监控 linux 内存使用状况最常用的指令
常见用法:free –m
[root@node1 ~]# free -mtotal used free shared buff/cache available
Mem: 1754 550 160 86 1044 937
Swap: 0 0 0
free –m表示以 M为单位查看内存使用情况,在这个输出中,我们重点关注的应该是 free 列与 cached 列的输出值,由输出可知,此系统共 2G 内存,系统空闲内存还有160M,其中,Buffer Cache 占用了 1044M,Page Cache 占用了 6299M,由此可知系统缓存了很多的文件和目录,而对于应用程序来说,可以使用的内存还有 7468M,当然这个 7468M 包含了 Buffer Cache 和 Page Cache 的值。在 swap 项可以看出,交换分区还未使用。所以从应用的角度来说,此系统内存资源还非常充足。
-
used:程序已使用内存
-
free:空闲内存
-
buffer/cache:是两个在计算机技术中被用滥的名词,放在不通语境下会有不同的意义。在 Linux 的内存管理中,这里的 buffer 指 Linux 内存的: Buffer cache 。这里的 cache 指 Linux 内存中的: Page cache 。翻译成中文可以叫做缓冲区缓存和页面缓存。在历史上,它们一个( buffer )被用来当成对 io 设备写的缓存,而另一个( cache )被用来当作对 io 设备的读缓存,这里的 io 设备,主要指的是块设备文件和文件系统上的普通文件。但是现在,它们的意义已经不一样了。在当前的内核中, page cache 顾名思义就是针对内存页的缓存,说白了就是,如果有内存是以 page 进行分配管理的,都可以使用 page cache 作为其缓存来管理使用。当然,不是所有的内存都是以页( page )进行管理的,也有很多是针对块( block )进行管理的,这部分内存使用如果要用到 cache 功能,则都集中到 buffer cache 中来使用。(从这个角度出发,是不是 buffer cache 改名叫做 block cache 更好?)然而,也不是所有块( block )都有固定长度,系统上块的长度主要是根据所使用的块设备决定的,而页长度在 X86 上无论是 32 位还是 64 位都是 4k 。
明白了这两套缓存系统的区别,就可以理解它们究竟都可以用来做什么了。
-
available:系统可用内存,之前说过由于buffer和cache可以在需要时被释放回收,系统可用内存即 free + buffer + cache,在CentOS7之后这种说法并不准确,因为并不是所有的buffer/cache空间都可以被回收。
即available = free + buffer/cache - 不可被回收内存(共享内存段、tmpfs、ramfs等)。
因此在CentOS7之后,用户不需要去计算buffer/cache,即
可以看到还有多少内存可用,更加简单直观。
一般有这样一个经验公式:
- 应用程序可用内存/系统物理内存>70%时,表示系统内存资源非常充足,不影响系统性能,
- 应用程序可用内存/系统物理内存<20%时,表示系统内存资源紧缺,需要增加系统内存,
- 20%<应用程序可用内存/系统物理内存<70%时,表示系统内存资源基本能满足应用需求,暂时不影响系统性能。
2. sar/pidstat
此两个命令主要用于监控全部或指定进程占用系统资源的情况,如 CPU,内存、设备IO。
三个公用参数:-u(获取 CPU 状态) 、-r(获取内存状态) 、-d(获取磁盘)
常用组合:
① sar -u 3 获取 cpu 3 秒内的状态
[root@node1 ~]# sar -u 3
Linux 3.10.0-1160.76.1.el7.x86_64 (node1) 03/13/2023 _x86_64_ (2 CPU)01:31:22 PM CPU %user %nice %system %iowait %steal %idle
01:31:25 PM all 0.00 0.00 0.17 0.00 0.00 99.83
01:31:28 PM all 0.00 0.00 0.00 0.00 0.00 100.00
01:31:31 PM all 0.00 0.00 0.17 0.00 0.00 99.83
01:31:34 PM all 0.00 0.00 0.00 0.00 0.00 100.00
[root@node1 ~]# sar -r 2 3
Linux 3.10.0-1160.76.1.el7.x86_64 (node1) 03/13/2023 _x86_64_ (2 CPU)01:33:44 PM kbmemfree kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
01:33:46 PM 163680 1633364 90.89 2172 960236 1656480 92.18 866316 407940 16
01:33:48 PM 163680 1633364 90.89 2172 960236 1656480 92.18 866320 407940 16
01:33:50 PM 163648 1633396 90.89 2172 960240 1656480 92.18 866320 407944 20
Average: 163669 1633375 90.89 2172 960237 1656480 92.18 866319 407941 17Kbmemfree 表示空闲物理内存大小,
kbmemused 表示已使用的物理内存空间大小,
%memused 表示已使用内存占总内存大小的百分比,
kbbuffers 和 kbcached 分别表示Buffer Cache 和 Page Cache 的大小,
kbcommit 和%commit 分别表示应用程序当前使用的内存大小和使用百分比。
可以看出 sar 的输出其实与 free的输出完全对应,不过 sar 更加人性化,不但给出了内存使用量,还给出了内存使用的百分比以及统计的平均值。从%commit 项可知,此系统目前内存资源并不充足。
② pidstat -r –p 1 3 获取内存 3 秒内的状态
[root@node1 ~]# pidstat -r -p 1 3
Linux 3.10.0-1160.76.1.el7.x86_64 (node1) 03/13/2023 _x86_64_ (2 CPU)01:32:42 PM UID PID minflt/s majflt/s VSZ RSS %MEM Command
01:32:45 PM 0 1 0.00 0.00 125756 4300 0.24 systemd
01:32:48 PM 0 1 0.00 0.00 125756 4300 0.24 systemd
01:32:51 PM 0 1 0.00 0.00 125756 4300 0.24 systemd
01:32:54 PM 0 1 0.00 0.00 125756 4300 0.24 systemd
01:32:57 PM 0 1 0.00 0.00 125756 4300 0.24 systemd
2.3 磁盘性能评估
1. iostat
通过“iostat –d”命令组合也可以查看系统磁盘的使用状况
iostat –d 2 2
统计2次磁盘信息,间隔2秒,第一个2表示间隔
[root@node1 ~]# iostat -d 2 2
Linux 3.10.0-1160.76.1.el7.x86_64 (node1) 03/14/2023 _x86_64_ (2 CPU)Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
scd0 0.00 0.00 0.00 1028 0
sda 0.11 1.34 0.95 655286 463636
sdb 0.03 0.06 0.77 29879 379101
sdc 0.00 0.01 0.00 6000 0
dm-0 0.15 1.33 1.72 651521 840578
dm-1 0.00 0.00 0.00 2072 0
dm-2 0.00 0.00 0.00 1036 0Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
scd0 0.00 0.00 0.00 0 0
sda 0.00 0.00 0.00 0 0
sdb 0.00 0.00 0.00 0 0
sdc 0.00 0.00 0.00 0 0
dm-0 0.00 0.00 0.00 0 0
dm-1 0.00 0.00 0.00 0 0
dm-2 0.00 0.00 0.00 0 0对上面每项的输出解释如下(单位kB):
- kB_read/s 表示每秒读取的数据量。
- kB_wrtn/s 表示每秒写入的数据量。
- kB_read 表示读取的所有数据量。
- kB_wrtn 表示写入的所有数据量。
2. pidstat (如上)
[root@node1 ~]# pidstat -d -p 1874 2 3
Linux 3.10.0-1160.76.1.el7.x86_64 (node1) 03/14/2023 _x86_64_ (2 CPU)04:54:38 AM UID PID kB_rd/s kB_wr/s kB_ccwr/s Command
04:54:40 AM 27 1874 0.00 0.00 0.00 mysqld
04:54:42 AM 27 1874 0.00 0.00 0.00 mysqld
04:54:44 AM 27 1874 0.00 0.00 0.00 mysqld
Average: 27 1874 0.00 0.00 0.00 mysqld3. sar(如上)
[root@dbc-server-554 zabbix]# sar -d 2 3
Linux 3.10.0-1160.83.1.el7.x86_64 (dbc-server-554) 03/14/2023 _x86_64_ (8 CPU)08:57:11 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
08:57:13 AM dev8-0 2.00 0.00 8.00 4.00 0.01 3.25 3.25 0.65
08:57:13 AM dev8-16 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
08:57:13 AM dev8-32 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
08:57:13 AM dev253-0 2.00 0.00 8.00 4.00 0.01 3.25 3.25 0.65
08:57:13 AM dev253-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
08:57:13 AM dev253-2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
08:57:13 AM dev253-3 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00...
对上面每项的输出解释如下:
- DEV 表示磁盘设备名称。
- tps 表示每秒到物理磁盘的传送数,也就是每秒的 I/O 流量。一个传送就是一个 I/O 请求,多个逻辑请求可以被合并为一个物理 I/O 请求。
- rd_sec/s 表示每秒从设备读取的扇区数(1 扇区=512 字节)。
- wr_sec/s 表示每秒写入设备的扇区数目。
- avgrq-sz 表示平均每次设备 I/O 操作的数据大小(以扇区为单位) 。
- avgqu-sz 表示平均 I/O 队列长度。
- await 表示平均每次设备 I/O 操作的等待时间(以毫秒为单位) 。
- svctm表示平均每次设备 I/O 操作的服务时间(以毫秒为单位) 。
- %util表示一秒中有百分之几的时间用于 I/O 操作。
Linux 中 I/O 请求系统与现实生活中超市购物排队系统有很多类似的地方,通过对超市购物排队系统的理解,可以很快掌握 linux 中 I/O 运行机制。比如:
- avgrq-sz 类似于超市排队中每人所买东西的多少。
- avgqu-sz 类似于超市排队中单位时间内平均排队的人数。
- await 类似于超市排队中每人的等待时间。
- svctm类似于超市排队中收银员的收款速度。
- %util类似于超市收银台前有人排队的时间比例。
对于磁盘 IO 性能,一般有如下评判标准:
-
正常情况下
svctm应该是小于await值的,而svctm的大小和磁盘性能有关,CPU、内存的负荷也会对 svctm值造成影响,过多的请求也会间接的导致 svctm值的增加。 -
await 值的大小一般取决于 svctm 的值和 I/O 队列长度以及 I/O 请求模式:
如果 svctm的值与 await 很接近,表示几乎没有 I/O 等待,磁盘性能很好
如果 await 的值远高于 svctm的值,则表示 I/O 队列等待太长,系统上运行的应用程序将变慢,此时可以通过更换更快的硬盘来解决问题。 -
%util 项的值也是衡量磁盘 I/O 的一个重要指标,如果%util 接近
100%,表示磁盘产生的 I/O 请求太多,I/O 系统已经满负荷的在工作,该磁盘可能存在瓶颈。长期下去,势必影响系统的性能,可以通过优化程序或者通过更换更高、更快的磁盘来解决此问题。
2.4 网络性能评估
1. ping
[root@dbc-server-554 zabbix]# ping 192.168.2.150
PING 192.168.2.150 (192.168.2.150) 56(84) bytes of data.
64 bytes from 192.168.2.150: icmp_seq=1 ttl=63 time=0.161 ms
64 bytes from 192.168.2.150: icmp_seq=2 ttl=63 time=0.173 ms
64 bytes from 192.168.2.150: icmp_seq=3 ttl=63 time=0.102 ms
64 bytes from 192.168.2.150: icmp_seq=4 ttl=63 time=0.135 ms
^C
--- 192.168.2.150 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 2999ms
rtt min/avg/max/mdev = 0.102/0.142/0.173/0.030 ms在这个输出中,time值显示了两台主机之间的网络延时情况,如果此值很大,则表示网络的延时很大,单位为毫秒。在这个输出的最后,是对上面输出信息的一个总结,packet loss 表示网络的丢包率,此值越小,表示网络的质量越高。
2. netstat
netstat –i (查看路由情况)
netstat –r(查看网络接口状态)
[root@dbc-server-554 zabbix]# netstat -i
Kernel Interface table
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
br-4a107b89632c 1500 47051931 0 0 0 54705220 0 0 0 BMU
br-7a074dc4b5d6 1500 0 0 0 0 0 0 0 0 BMU
br-c0ba7b9c2a7c 1500 0 0 0 0 0 0 0 0 BMU
br-c59bd6f64464 1500 47051931 0 0 0 54705220 0 0 0 BMU
br-d44dbcba5be7 1500 47051931 0 0 0 54705220 0 0 0 BMU
docker0 1500 0 0 0 0 0 0 0 0 BMU
docker_gwbridge 1500 47051931 0 0 0 54705220 0 0 0 BMU
enp3s0 1500 47051931 0 0 0 54705220 0 0 0 BMRU
lo 65536 16495359 0 0 0 16495359 0 0 0 LRU
virbr0 1500 0 0 0 0 0 0 0 0 BMU
[root@dbc-server-554 zabbix]# netstat -r
Kernel IP routing table
Destination Gateway Genmask Flags MSS Window irtt Iface
default gateway 0.0.0.0 UG 0 0 0 enp3s0
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
172.18.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker_gwbridge
172.19.0.0 0.0.0.0 255.255.0.0 U 0 0 0 br-7a074dc4b5d6
172.20.0.0 0.0.0.0 255.255.0.0 U 0 0 0 br-4a107b89632c
172.22.0.0 0.0.0.0 255.255.0.0 U 0 0 0 br-c59bd6f64464
172.24.0.0 0.0.0.0 255.255.0.0 U 0 0 0 br-c0ba7b9c2a7c
172.25.0.0 0.0.0.0 255.255.0.0 U 0 0 0 br-d44dbcba5be7
192.168.5.0 0.0.0.0 255.255.255.0 U 0 0 0 enp3s0
192.168.122.0 0.0.0.0 255.255.255.0 U 0 0 0 virbr0
3. mtr/traceroute 命令
跟踪网络路由状态,推荐使用 mtr,动态跟踪网络路由,用于排除网络问题非常方便。
My traceroute [v0.85]
dbc-server-554 (0.0.0.0) Tue Mar 14 10:08:51 2023
Keys: Help Display mode Restart statistics Order of fields quitPackets PingsHost Loss% Snt Last Avg Best Wrst StDev1. ???2. 192.168.2.150 0.0% 25 0.2 0.2 0.1 0.3 0.0
[root@dbc-server-554 zabbix]# traceroute -4 192.168.2.150
traceroute to 192.168.2.150 (192.168.2.150), 30 hops max, 60 byte packets1 * * *2 192.168.2.150 (192.168.2.150) 0.130 ms 0.119 ms 0.096 ms
3. 系统性能分析标准
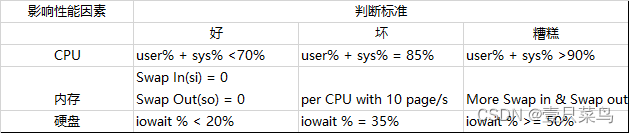
- user%:表示CPU处在用户模式下的时间百分比
- sys%:表示CPU处在系统模式下的时间百分比
- iowait%:表示CPU等待输入输出的时间百分比
- swap in:即si,表示虚拟内存的页导入,即从SWAP DISK交换到RAM
<持续更新---->