hadoop基础安装(二) 包含免登录ssh
(1)在 hadoop102 安装 Hadoop
为什么是 102 ,100 用户单机测试,101 用户虚拟集群测试,102-104用于真实集群测试
Hadoop 下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/
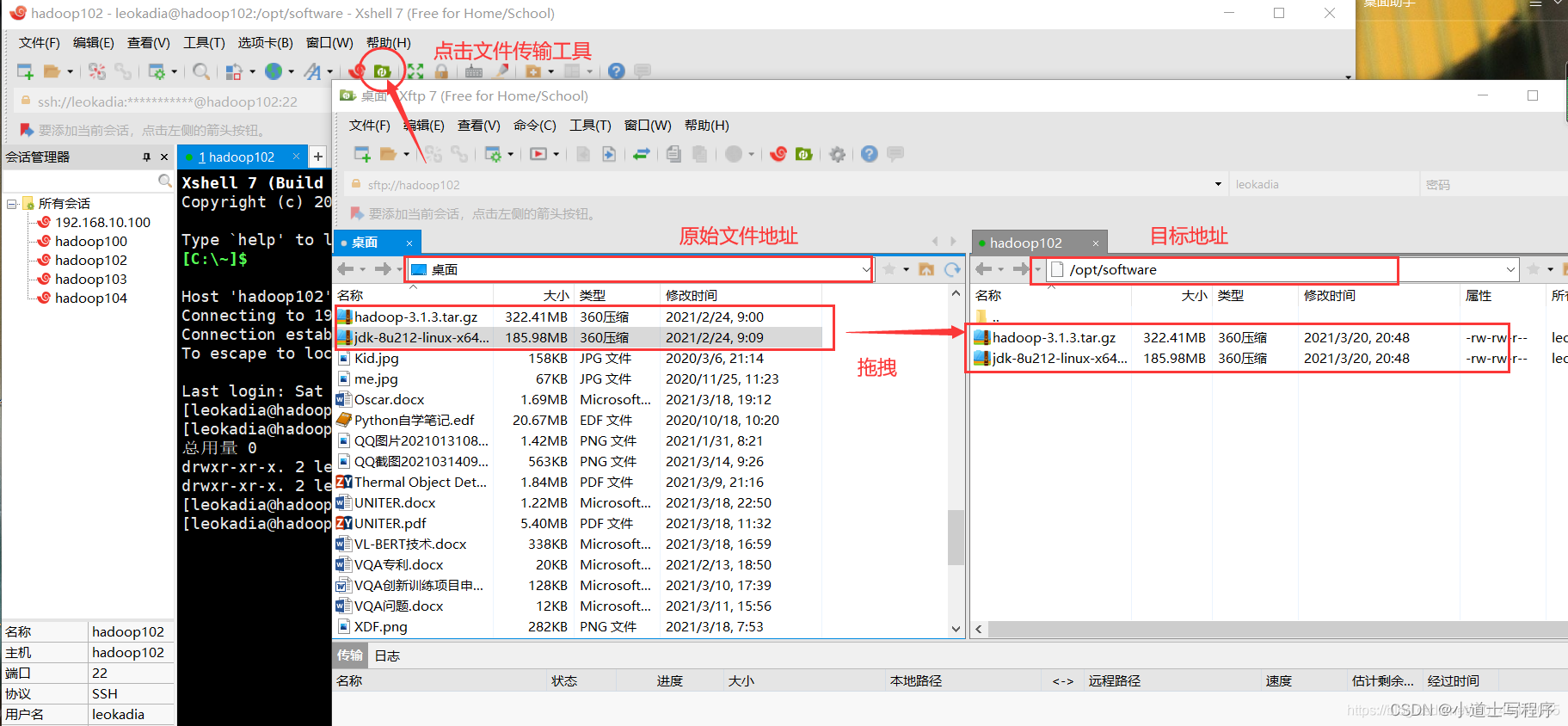
(2 ) 用 XShell 文件传输 工具将 hadoop-3.1.3.tar.gz 导入到 opt 目录下面的 software 文件夹下面
(3)解压缩到 /usr/local/ ,hadoop 安装同jdk
tar xzvf jdkxxx.jar -C /usr/local ,
(3)将 Hadoop 添加到环境变量
(1)获取 Hadoop 安装路径
[leokadia@hadoop102 hadoop-3.1.3]$ pwd
/usr/local/hadoop-3.1.3
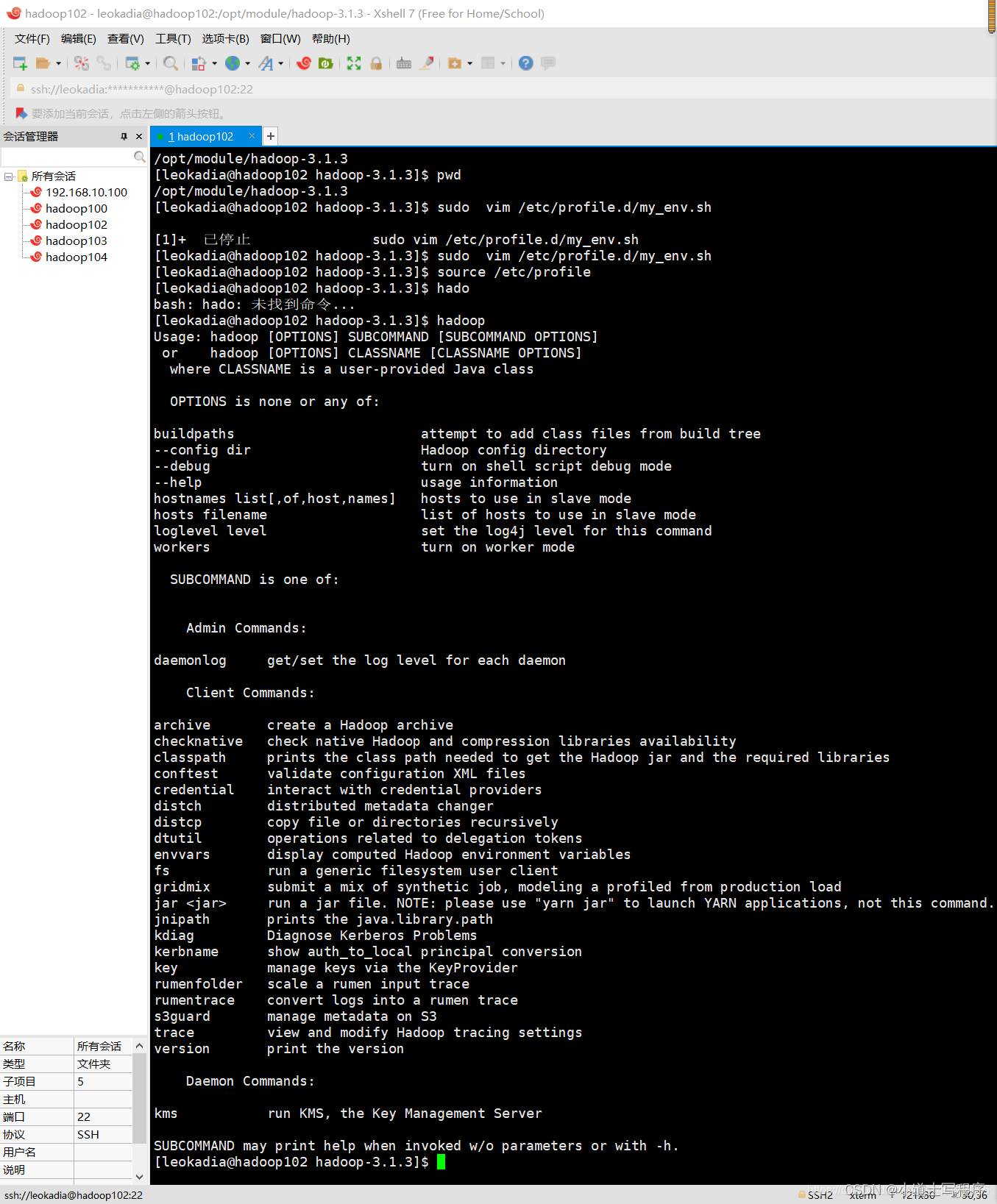
(2)打开/etc/profile.d/my_env.sh 文件
[leokadia@hadoop102 hadoop-3.1.3]$ sudo vim /etc/profile.d/my_env.sh
➢ 在 my_env.sh 文件末尾添加如下内容:(shift+g)
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin 生效:source /etc/profile
测试:hadoop version
重要目录
(1)bin 目录:存放对 Hadoop 相关服务(hdfs,yarn,mapred)进行操作的脚本
(2)etc 目录:Hadoop 的配置文件目录,存放 Hadoop 的配置文件
(3)lib 目录:存放 Hadoop 的本地库(对数据进行压缩解压缩功能)
(4)sbin 目录:存放启动或停止 Hadoop 相关服务的脚本
(5)share 目录:存放 Hadoop 的依赖 jar 包、文档、和官方案例
(4)送一套多服务器发布脚本
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
thenecho Not Enough Arguement!exit;
fi#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
doecho ==================== $host ====================#3. 遍历所有目录,挨个发送for file in $@do#4. 判断文件是否存在if [ -e $file ]then#5. 获取父目录pdir=$(cd -P $(dirname $file); pwd)#6. 获取当前文件的名称fname=$(basename $file)ssh $host "mkdir -p $pdir"rsync -av $pdir/$fname $host:$pdirelseecho $file does not exists!fidone
done 使用规则: xsync 需要加到 PATH中。
xsync /etc/profile.d/my_evn.sh
如果机器没有安装 rsync,记得运行 102,103,104 都要安装;
yum -y install rsync
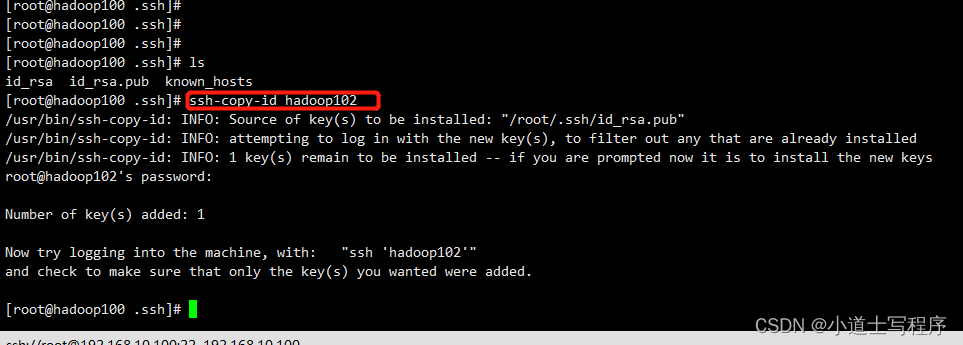
(5)免密登录
cd ~
cd .ssh
ssh-keygen -t rsa (三次回车)
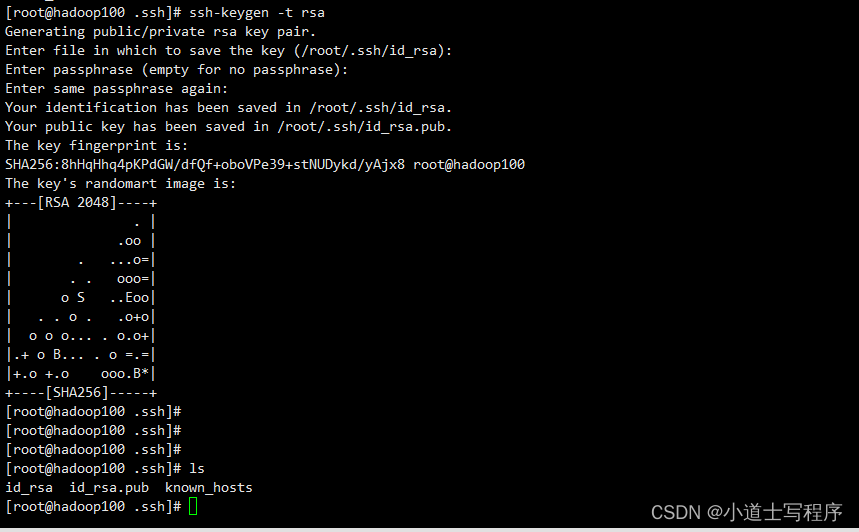
ssh-copy-id hadoop102 (把公钥给102,103,104)