论文阅读:MPViT : Multi-Path Vision Transformer for Dense Prediction
创始人
2025-05-30 19:01:37
中文标题:基于多路视觉Transformer的密集预测
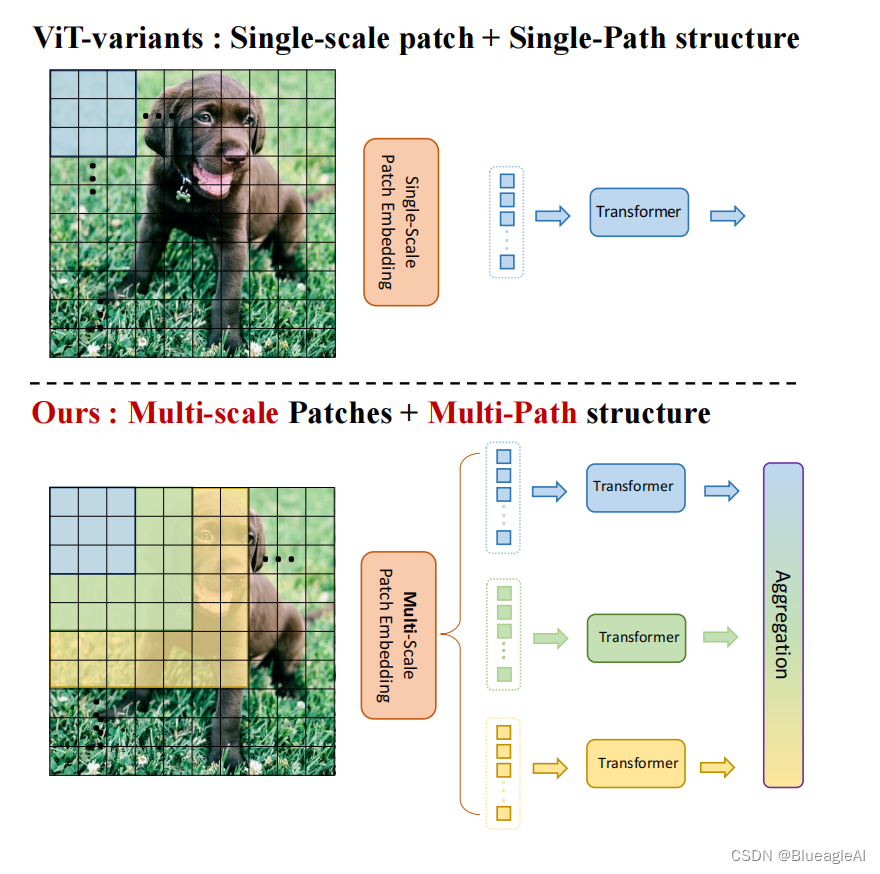
提出问题
创新点
- 提出了一种具有多路径结构的多尺度嵌入方法,以同时表示密集预测任务的精细和粗糙特征。
- 全局到局部的特征交互(GLI),以同时利用卷积的局部连通性和转换器的全局上下文。
网络结构
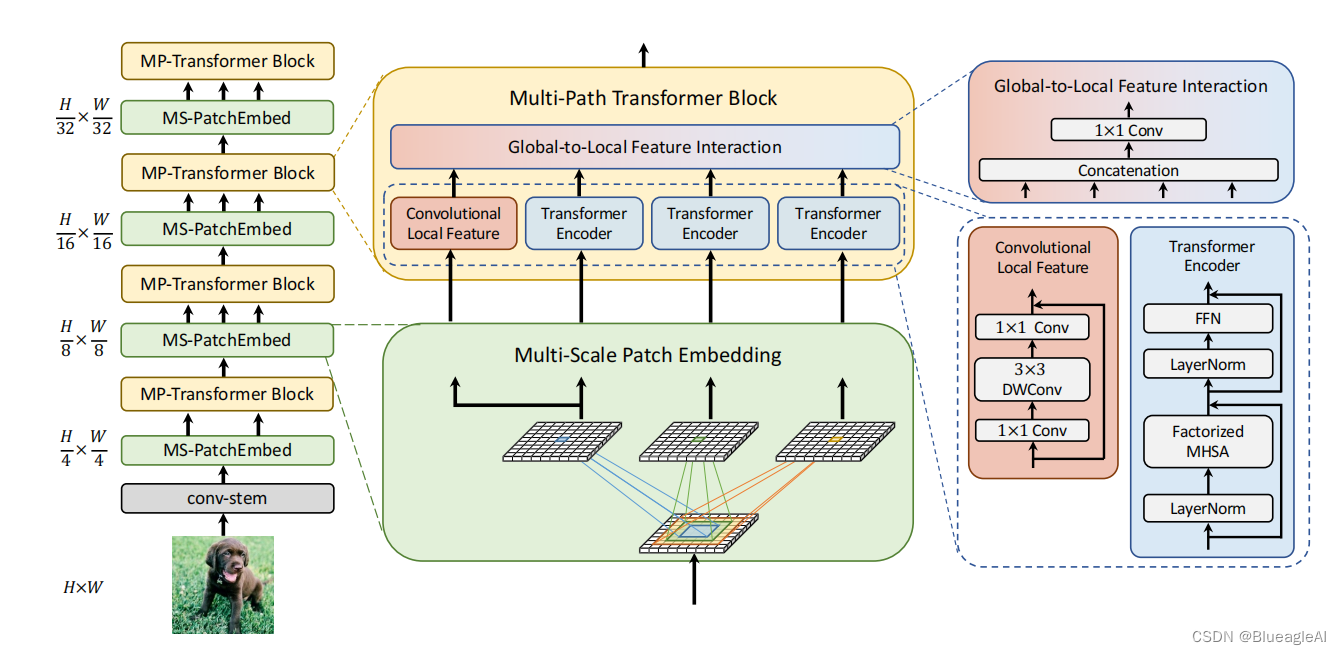
- 建立了一个四阶段的特征层次图来生成不同尺度的特征映射。
- 步骤:
- 第1层:对于输入HxWx3,我们设计了一个由两个3x3,步长为4,输出通道数为C2C_2C2的卷积。
- 第2-5层:反复叠加MS-PatchEmbed(multi-scale patch embedding)以及MP-Transformer(multi-path Transformer)
Multi-Scale Patch Embedding
- 输入特征Xi∈RHi−1×Wi−1×Ci−1X_i \in \mathbb{R}^{H_{i-1} \times W_{i-1} \times C_{i-1}}Xi∈RHi−1×Wi−1×Ci−1, 学习一个Fk×k(⋅)F_{k\times k}(·)Fk×k(⋅)将XiX_iXi排布成新Tokens Fk×k∈RHi×Wi×CiF_{k \times k} \in \mathbb{R}^{H_{i} \times W_{i} \times C_{i}}Fk×k∈RHi×Wi×Ci,它的通道数为CiC_iCi。F的构型为一个大小k×kk \times kk×k,步长s,padding为p的卷积。
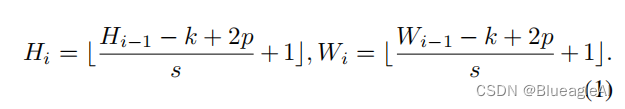
- 通过改变k×kk \times kk×k的大叫改变Patch的尺寸。卷积补丁嵌入层使我们能够通过改变stride和padding来调整标记的序列长度(输出尺寸)。
- 接着我们得到F3×3,F5×5,F7×7F_{3\times 3}, F_{5\times 5},F_{7\times 7}F3×3,F5×5,F7×7
Global-to-Local Feature Interaction
- 虽然变形金刚中的自我关注可以捕获大范围依赖关系(即全局上下文),但它很可能会忽略每个补丁中的结构性信息和局部关系。
- 此外,Transformer受益于shape-bias[52],允许他们专注于图像的重要部分。
[52]卷积神经网络利用滤波器将图像中的Patchs赋予相同的权重,这类似于视觉皮层中的一个神经元对特定刺激的反应。通过训练这些滤波器的权值,CNN可以学习每个特定类别的图像表示,并已被证明与视觉皮层的处理有许多相似之处。然而,这种局部连通性可能会导致全局环境的丢失;例如,它可能会鼓励人们倾向于根据纹理而不是形状进行分类。
而Transformer则是以自监督为主干,这种机制允许我们在上下文(不同patch间)中增强某些信息的相关性。
- 卷积可以利用平移不变性中的局部连通性——图像中的每个补丁都由相同的权值处理。这种归纳偏差鼓励CNN在对视觉对象进行分类时,对纹理有更强的依赖性,而不是形状。
- 因此,MPViT以一种互补的方式将cnn的局部连接与全局上下文转换器结合起来。
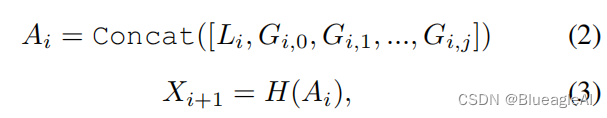
- 分别使用卷积以及Transformer对tokens Fk×kF_{k \times k}Fk×k提取特征。H(⋅)H(·)H(⋅)是特征通道融合器。
参考文献
[1] Lee Y, Kim J, Willette J, et al. Mpvit: Multi-path vision transformer for dense prediction[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 7287-7296.
[52] Shikhar Tuli, Ishita Dasgupta, Erin Grant, and Thomas L Griffiths. Are convolutional neural networks or transformers more like human vision? arXiv preprint arXiv:2105.07197, 2021. 4
相关内容
热门资讯
美乌德三方代表在德国总理府开始...
△乌克兰总统泽连斯基(右)与美国总统特使威特科夫(左)握手 当地时间14日下午,乌克兰总统泽连斯基与...
聊聊周期性行业的巨大波动
这周的A股确实是没啥好说的,该说的都说了,只能换个话题。上上周五,A股收盘3888点,上周五是390...
产地造假、年份速成、无视监管!...
(央视财经《财经调查》)《财经调查》栏目接到群众举报,反映陈皮市场存在年份虚标、产地及工艺造假等问题...
财经调查丨千元假陈皮成本仅70...
(央视财经《财经调查》)总台《财经调查》栏目接到群众举报,反映陈皮市场存在年份虚标、产地及工艺造假等...
澳大利亚总理:邦迪海滩枪击事件...
△澳大利亚总理阿尔巴尼斯(资料图) 当地时间14日,澳大利亚总理阿尔巴尼斯说,当天发生在悉尼邦迪海滩...