【超详细】MMLab分类任务mmclassification:环境配置说明、训练、预测及模型结果可视化展示
本文详细介绍了使用MMLab的mmclassification进行分类任务的环境配置、训练与预测流程。
目录
- 文件配置说明
- 下载源码
- 配置文件
- 基于预训练模型微调或者续训练自己模型的方式
- 配置文件说明
- 数据集配置方式
- 更改配置文件中的类别名称
- 训练模型
- 模型预测
- 可视化展示
- 数据增强可视化
- 特征可视化--vis_cam.py文件
- 结果日志分析工具
文件配置说明
如果没有自己数据集练习的小伙伴,可以通过下面方式获取我用于训练测试的数据集,跟着本文一起练习一下整个流程,这个数据集是用于训练102种花朵分类识别的数据集。
关注GZH:阿旭算法与机器学习,回复:【mmlab实战1】即可获取已经下载好的mmlabclassification源码与demo训练用的数据:数据在mmcls/data目录中,已经放置好了
下载源码
先下载mmlabclassification源码到本地:
下载链接:https://github.com/open-mmlab/mmclassification。
目录如下:
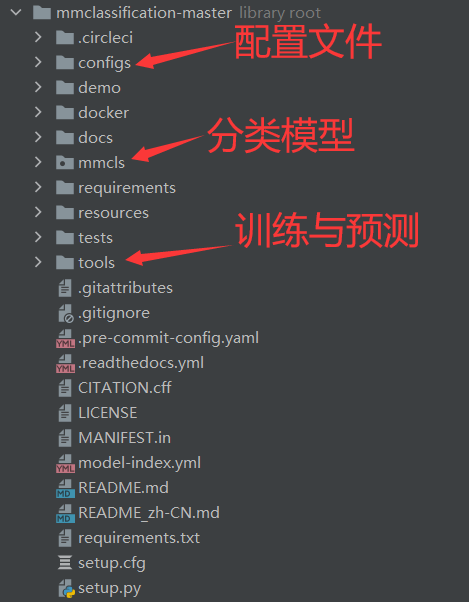
配置文件
在config里面选择想要使用的模型,并打开相应配置文件,比如使用resnet模型中的resnet18_8xb32_in1k.py这个模型:
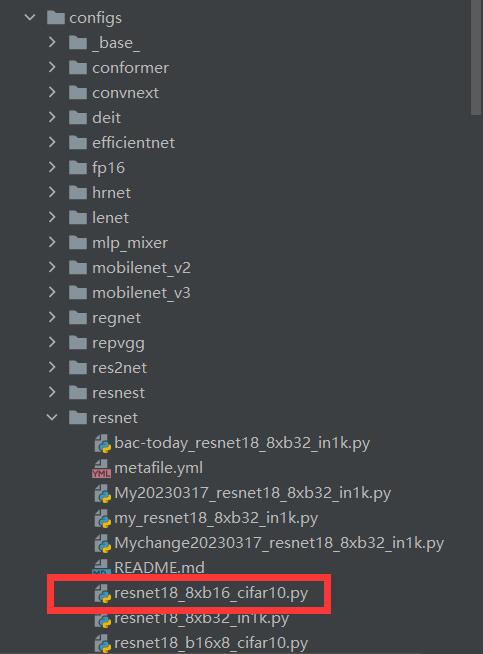
打开resnet18_8xb32_in1k.py这个文件,显示如下:
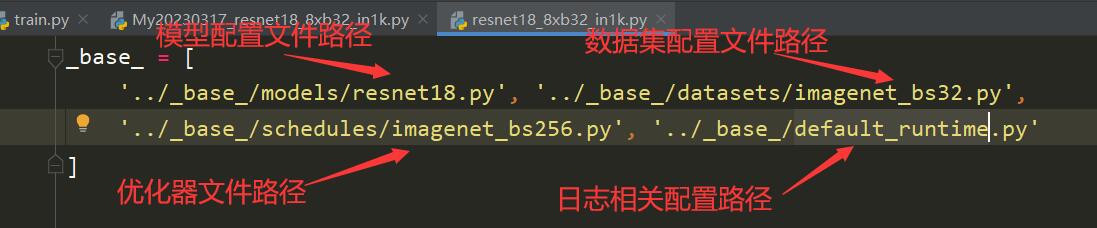
上面几个配置文件都在config / _ base _ 目录下,
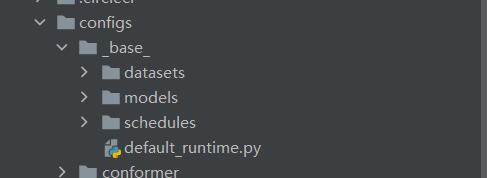
上面4个文件,可分别按需求进行配置,但是一个个配置很麻烦,有一个简单的方法可以生成一个总的配置文件,方法如下。
直接将上面选的resnet18_8xb32_in1k.py作为配置参数,运行一遍tools/train.py,因为很多参数没配置,故肯定报错,但是会得到一个完整版的配置文件,存放在tools\work_dirs中,如下图:(生成的配置文件名字与你运行的配置文件名称默认是相同的)
新的完整配置文件resnet18_8xb32_in1k.py内容如下:(注:这个与之前那个resnet18_8xb32_in1k.py文件不是同一个,只是名字一样)
需要修改的内容如下:
1.修改分类数目:num_classes
2.修改数据集配置路径
基于预训练模型微调或者续训练自己模型的方式
resnet18_8xb32_in1k.py配置文件中:
load_from = None:load_from 可以用于指定别人预训练好的基模型,在此基础上进行参数微调训练
resume_from = None:resume_from 参数,可以指定之前训练过的模型,在此基础上接着训练。
model = dict(type='ImageClassifier',backbone=dict(type='ResNet',depth=18,num_stages=4,out_indices=(3, ),style='pytorch'),neck=dict(type='GlobalAveragePooling'),head=dict(type='LinearClsHead',num_classes=1000,in_channels=512,loss=dict(type='CrossEntropyLoss', loss_weight=1.0),topk=(1, 5)))
dataset_type = 'ImageNet'
img_norm_cfg = dict(mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [dict(type='LoadImageFromFile'),dict(type='RandomResizedCrop', size=224),dict(type='RandomFlip', flip_prob=0.5, direction='horizontal'),dict(type='Normalize',mean=[123.675, 116.28, 103.53],std=[58.395, 57.12, 57.375],to_rgb=True),dict(type='ImageToTensor', keys=['img']),dict(type='ToTensor', keys=['gt_label']),dict(type='Collect', keys=['img', 'gt_label'])
]
test_pipeline = [dict(type='LoadImageFromFile'),dict(type='Resize', size=(256, -1)),dict(type='CenterCrop', crop_size=224),dict(type='Normalize',mean=[123.675, 116.28, 103.53],std=[58.395, 57.12, 57.375],to_rgb=True),dict(type='ImageToTensor', keys=['img']),dict(type='Collect', keys=['img'])
]
data = dict(samples_per_gpu=32,workers_per_gpu=2,train=dict(type='ImageNet',data_prefix='data/imagenet/train',pipeline=[dict(type='LoadImageFromFile'),dict(type='RandomResizedCrop', size=224),dict(type='RandomFlip', flip_prob=0.5, direction='horizontal'),dict(type='Normalize',mean=[123.675, 116.28, 103.53],std=[58.395, 57.12, 57.375],to_rgb=True),dict(type='ImageToTensor', keys=['img']),dict(type='ToTensor', keys=['gt_label']),dict(type='Collect', keys=['img', 'gt_label'])]),val=dict(type='ImageNet',data_prefix='data/imagenet/val',ann_file='data/imagenet/meta/val.txt',pipeline=[dict(type='LoadImageFromFile'),dict(type='Resize', size=(256, -1)),dict(type='CenterCrop', crop_size=224),dict(type='Normalize',mean=[123.675, 116.28, 103.53],std=[58.395, 57.12, 57.375],to_rgb=True),dict(type='ImageToTensor', keys=['img']),dict(type='Collect', keys=['img'])]),test=dict(type='ImageNet',data_prefix='data/imagenet/val',ann_file='data/imagenet/meta/val.txt',pipeline=[dict(type='LoadImageFromFile'),dict(type='Resize', size=(256, -1)),dict(type='CenterCrop', crop_size=224),dict(type='Normalize',mean=[123.675, 116.28, 103.53],std=[58.395, 57.12, 57.375],to_rgb=True),dict(type='ImageToTensor', keys=['img']),dict(type='Collect', keys=['img'])]))
evaluation = dict(interval=1, metric='accuracy')
optimizer = dict(type='SGD', lr=0.1, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict(grad_clip=None)
lr_config = dict(policy='step', step=[30, 60, 90])
runner = dict(type='EpochBasedRunner', max_epochs=100)
checkpoint_config = dict(interval=1)
log_config = dict(interval=100, hooks=[dict(type='TextLoggerHook')])
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = None
resume_from = None
workflow = [('train', 1)]
work_dir = './work_dirs\\resnet18_8xb32_in1k'
gpu_ids = [0]
配置文件说明
model = dict(type='ImageClassifier', # 分类器类型backbone=dict(type='ResNet', # 主干网络类型depth=50, # 主干网网络深度, ResNet 一般有18, 34, 50, 101, 152 可以选择num_stages=4, # 主干网络状态(stages)的数目,这些状态产生的特征图作为后续的 head 的输入。out_indices=(3, ), # 输出的特征图输出索引。越远离输入图像,索引越大frozen_stages=-1, # 网络微调时,冻结网络的stage(训练时不执行反相传播算法),若num_stages=4,backbone包含stem 与 4 个 stages。frozen_stages为-1时,不冻结网络; 为0时,冻结 stem; 为1时,冻结 stem 和 stage1; 为4时,冻结整个backbonestyle='pytorch'), # 主干网络的风格,'pytorch' 意思是步长为2的层为 3x3 卷积, 'caffe' 意思是步长为2的层为 1x1 卷积。neck=dict(type='GlobalAveragePooling'), # 颈网络类型head=dict(type='LinearClsHead', # 线性分类头,num_classes=1000, # 输出类别数,这与数据集的类别数一致in_channels=2048, # 输入通道数,这与 neck 的输出通道一致loss=dict(type='CrossEntropyLoss', loss_weight=1.0), # 损失函数配置信息topk=(1, 5),)) # 评估指标,Top-k 准确率, 这里为 top1 与 top5 准确率
通常可设置参数内容:num-classes必须依据自己的实际分类数修改,其他可以不动。
可以调试out_indices,(0 1 2 3),4层可调试,这里取得是最深层3,特征金字塔输出多个;
num_classes: 设置自己数据集的类别个数;(必须修改)
neck颈部网络也可调试;
损失函数可以调试。
# dataset settings
dataset_type = 'ImageNet' # 数据集名称,
img_norm_cfg = dict( #图像归一化配置,用来归一化输入的图像。mean=[123.675, 116.28, 103.53], # 预训练里用于预训练主干网络模型的平均值。std=[58.395, 57.12, 57.375], # 预训练里用于预训练主干网络模型的标准差。to_rgb=True) # 是否反转通道,使用 cv2, mmcv 读取图片默认为 BGR 通道顺序,这里 Normalize 均值方差数组的数值是以 RGB 通道顺序, 因此需要反转通道顺序。
# 训练数据流水线
train_pipeline = [dict(type='LoadImageFromFile'), # 读取图片dict(type='RandomResizedCrop', size=224), # 随机缩放抠图dict(type='RandomFlip', flip_prob=0.5, direction='horizontal'), # 以概率为0.5随机水平翻转图片dict(type='Normalize', **img_norm_cfg), # 归一化dict(type='ImageToTensor', keys=['img']), # image 转为 torch.Tensordict(type='ToTensor', keys=['gt_label']), # gt_label 转为 torch.Tensordict(type='Collect', keys=['img', 'gt_label']) # 决定数据中哪些键应该传递给检测器的流程
]
# 测试数据流水线
test_pipeline = [dict(type='LoadImageFromFile'),dict(type='Resize', size=(256, -1)),dict(type='CenterCrop', crop_size=224),dict(type='Normalize', **img_norm_cfg),dict(type='ImageToTensor', keys=['img']),dict(type='Collect', keys=['img']) # test 时不传递 gt_label
]
data = dict(samples_per_gpu=32, # 单个 GPU 的 Batch sizeworkers_per_gpu=2, # 单个 GPU 的 线程数train=dict( # 训练数据信息type=dataset_type, # 数据集名称data_prefix='data/imagenet/train', # 数据集目录,当不存在 ann_file 时,类别信息从文件夹自动获取pipeline=train_pipeline), # 数据集需要经过的 数据流水线
val=dict( # 验证数据集信息type=dataset_type,data_prefix='data/imagenet/val',ann_file='data/imagenet/meta/val.txt', # 标注文件路径,存在 ann_file 时,不通过文件夹自动获取类别信息pipeline=test_pipeline),
test=dict( # 测试数据集信息type=dataset_type,data_prefix='data/imagenet/val',ann_file='data/imagenet/meta/val.txt',pipeline=test_pipeline))
evaluation = dict( # evaluation hook 的配置interval=1, # 验证期间的间隔,单位为 epoch 或者 iter, 取决于 runner 类型。metric='accuracy') # 验证期间使用的指标。
上面主要需要修改:训练数据data,验证集val,测试集test这几个数据集的路径。(数据集路径配置方式见下文)
# Checkpoint hook 的配置文件。
checkpoint_config = dict(interval=1) # 保存的间隔是 1,单位会根据 runner 不同变动,可以为 epoch 或者 iter。
# 日志配置信息。
log_config = dict(interval=100, # 打印日志的间隔, 单位 itershooks=[dict(type='TextLoggerHook'), # 用于记录训练过程的文本记录器(logger)。# dict(type='TensorboardLoggerHook') # 同样支持 Tensorboard 日志])dist_params = dict(backend='nccl') # 用于设置分布式训练的参数,端口也同样可被设置。
log_level = 'INFO' # 日志的输出级别。
resume_from = None # 从给定路径里恢复检查点(checkpoints),训练模式将从检查点保存的轮次开始恢复训练。
workflow = [('train', 1)] # runner 的工作流程,[('train', 1)] 表示只有一个工作流且工作流仅执行一次。
work_dir = 'work_dir' # 用于保存当前实验的模型检查点和日志的目录文件地址。
# 用于构建优化器的配置文件。支持 PyTorch 中的所有优化器,同时它们的参数与 PyTorch 里的优化器参数一致。
optimizer = dict(type='SGD', # 优化器类型lr=0.1, # 优化器的学习率,参数的使用细节请参照对应的 PyTorch 文档。momentum=0.9, # 动量(Momentum)weight_decay=0.0001) # 权重衰减系数(weight decay)。# optimizer hook 的配置文件
optimizer_config = dict(grad_clip=None) # 大多数方法不使用梯度限制(grad_clip)。
# 学习率调整配置,用于注册 LrUpdater hook。
lr_config = dict(policy='step', # 调度流程(scheduler)的策略,也支持 CosineAnnealing, Cyclic, 等。step=[30, 60, 90]) # 在 epoch 为 30, 60, 90 时, lr 进行衰减
runner = dict(type='EpochBasedRunner', # 将使用的 runner 的类别,如 IterBasedRunner 或 EpochBasedRunner。max_epochs=100) # runner 总回合数, 对于 IterBasedRunner 使用 `max_iters`
数据集配置方式
数据集配置方式有以下两种:
方式一:直接用文件夹名称作为标签,只需配置data_prefix这一个路径参数,格式如下:

自己创建一个data目录,目录下有train,valid,test三个文件夹,这3个文件夹下放置每个分类类别的目录文件(以类别命名文件夹),每个目录1-7中存放的就是当前目录文件名标签1-7对应的图片:(目录数字1-7直接替换为需要预测的类别名称即可:代表目录下图片所属的标签名称)
目录结构如下:
这种方式data配置文件的设置方式如下:只需配置数据路径data_prefix,不需要标签路径:ann_file,因为此时会默认用图片所在的目录名称作为标签。
data = dict(samples_per_gpu=32, # 单个 GPU 的 Batch sizeworkers_per_gpu=2, # 单个 GPU 的 线程数train=dict( # 训练数据信息type=dataset_type, # 数据集名称data_prefix='data/train', # 数据集目录,当不存在 ann_file 时,类别信息从文件夹自动获取pipeline=train_pipeline), # 数据集需要经过的 数据流水线
val=dict( # 验证数据集信息type=dataset_type,data_prefix='data/val',pipeline=test_pipeline),
test=dict( # 测试数据集信息type=dataset_type,data_prefix='data/test',pipeline=test_pipeline))
evaluation = dict( # evaluation hook 的配置interval=1, # 验证期间的间隔,单位为 epoch 或者 iter, 取决于 runner 类型。metric='accuracy') # 验证期间使用的指标。
方式二:所有图片均在一个目录下,没有区分标签目录,此时需要构建图片与标签一一对应的.txt文件。,这种方式配置起来稍微复杂一点。

自己创建一个data目录,目录下有train,valid,test三个文件夹,这3个目录下分别放需要训练、验证与测试的图片。不用像方法一一样建立分类子目录,不过此时需要通过分别构建train.txt, val.txt, test.txt这3个文件获取图片所对应的标签。
.txt文件格式如下:【图片名 类别】
注:类别是从0开始依次向后编号的。编号对应的实际名称是在mmcls/datasets/imagenet.py这个文件中设置的。(下文会讲)
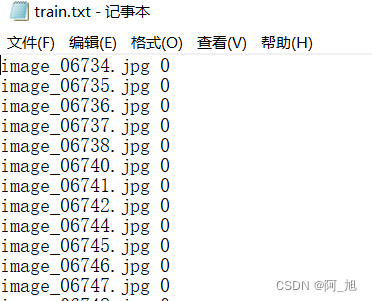
这种方式data配置文件需要同时配置数据路径data_prefix,标签路径:ann_file。如下:
data = dict(samples_per_gpu=32, # 单个 GPU 的 Batch sizeworkers_per_gpu=2, # 单个 GPU 的 线程数train=dict( # 训练数据信息type=dataset_type, # 数据集名称data_prefix='data/train', # 数据集目录,当不存在 ann_file 时,类别信息从文件夹自动获取ann_file='data/train.txt',pipeline=train_pipeline), # 数据集需要经过的 数据流水线
val=dict( # 验证数据集信息type=dataset_type,data_prefix='data/val',ann_file='data/val.txt',pipeline=test_pipeline),
test=dict( # 测试数据集信息type=dataset_type,data_prefix='data/test',ann_file='data/test.txt',pipeline=test_pipeline))
evaluation = dict( # evaluation hook 的配置interval=1, # 验证期间的间隔,单位为 epoch 或者 iter, 取决于 runner 类型。metric='accuracy') # 验证期间使用的指标。
注:实际数据路径根据你防止数据集的位置进行修改。
这种方式还需要建立自己读文件的类,进行文件读取:
在mmcls/datasets目录下,创建file_list.py文件,内容如下:
import numpy as npfrom .builder import DATASETS
from .base_dataset import BaseDataset@DATASETS.register_module()
class MyFilelist(BaseDataset):CLASSES = ['flower_'+ str(i) for i in range(102)]def load_annotations(self):assert isinstance(self.ann_file, str)data_infos = []with open(self.ann_file) as f:samples = [x.strip().split(' ') for x in f.readlines()]for filename, gt_label in samples:info = {'img_prefix': self.data_prefix}info['img_info'] = {'filename': filename}info['gt_label'] = np.array(gt_label, dtype=np.int64)data_infos.append(info)return data_infos
然后在mmcls/datasets/init.py 中完成注册,如下图:
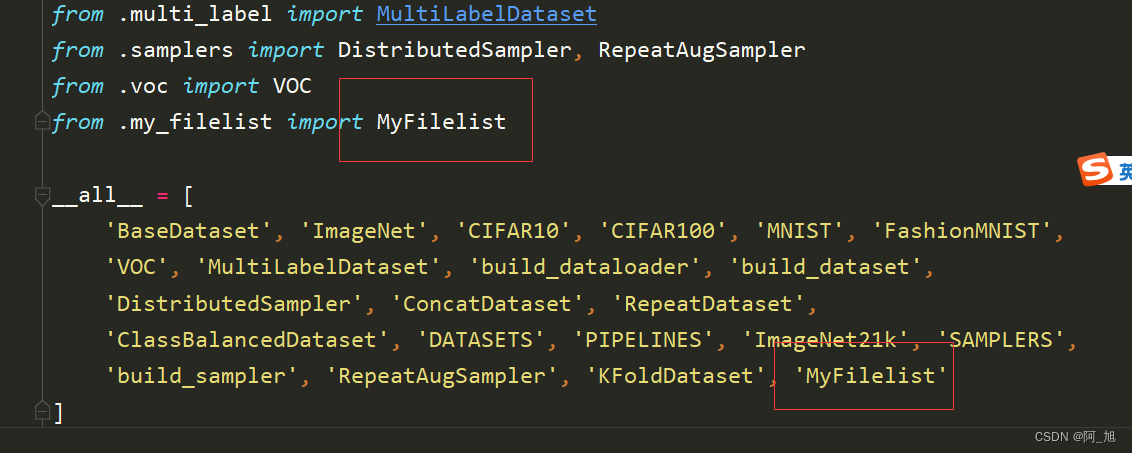
然后下修改tools\work_dirs\esnet18_8xb32_in1k\esnet18_8xb32_in1k.py这个配置文件中data读取的类名,如下图:
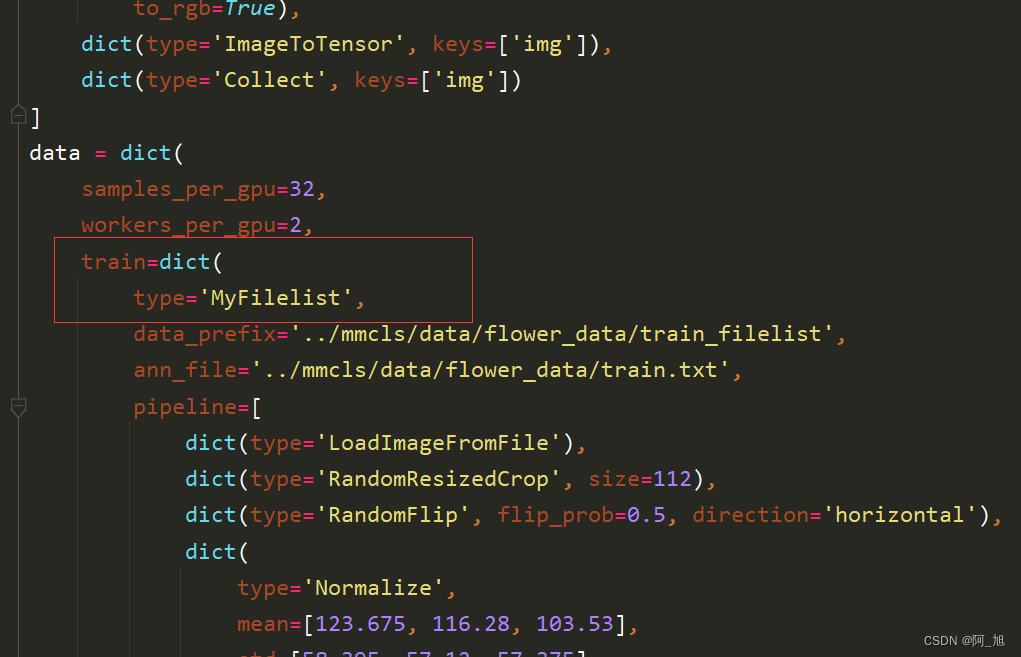
更改配置文件中的类别名称
各个编号对应类别实际名称在mmcls/datasets/imagenet.py这个文件中设置:
更改ImageNet类中的CLASSES为自己需要分类的类别名称列表:
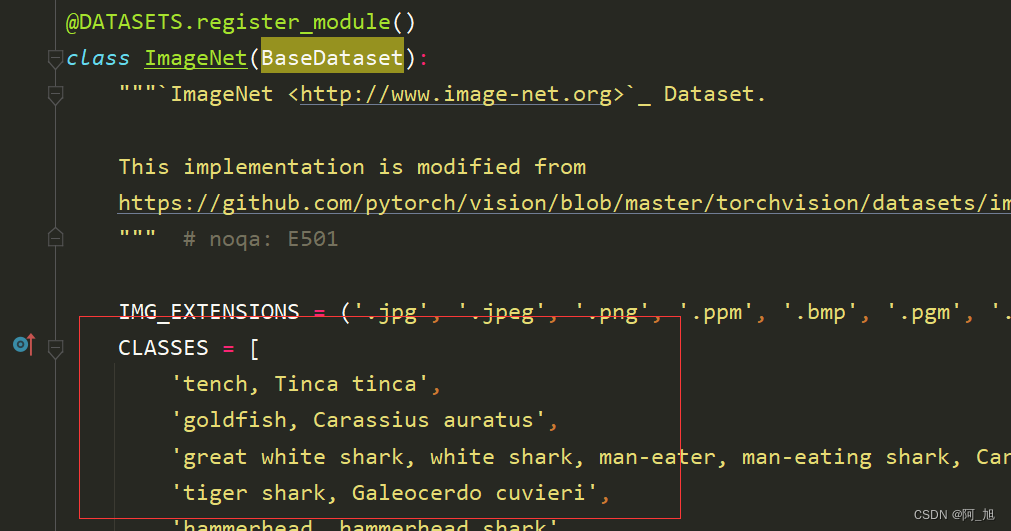
到此配置文件修改完毕,然后就可以用tools\work_dirs\resnet18_8xb32_in1k.py这个完整的配置文件运行我们的train.py训练模型。
训练模型
pycharm中点击下面配置按钮
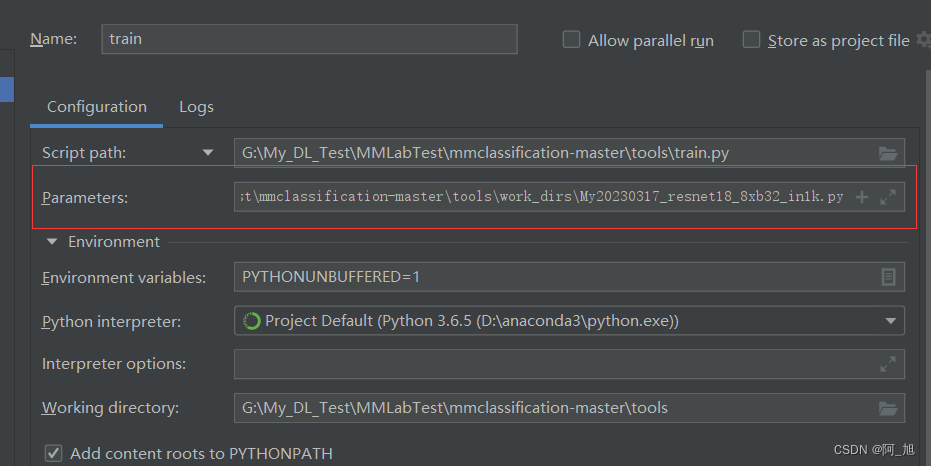
在参数这里输入tools\work_dirs\resnet18_8xb32_in1k.py这个的绝对路径,就可以对模型进行训练了。
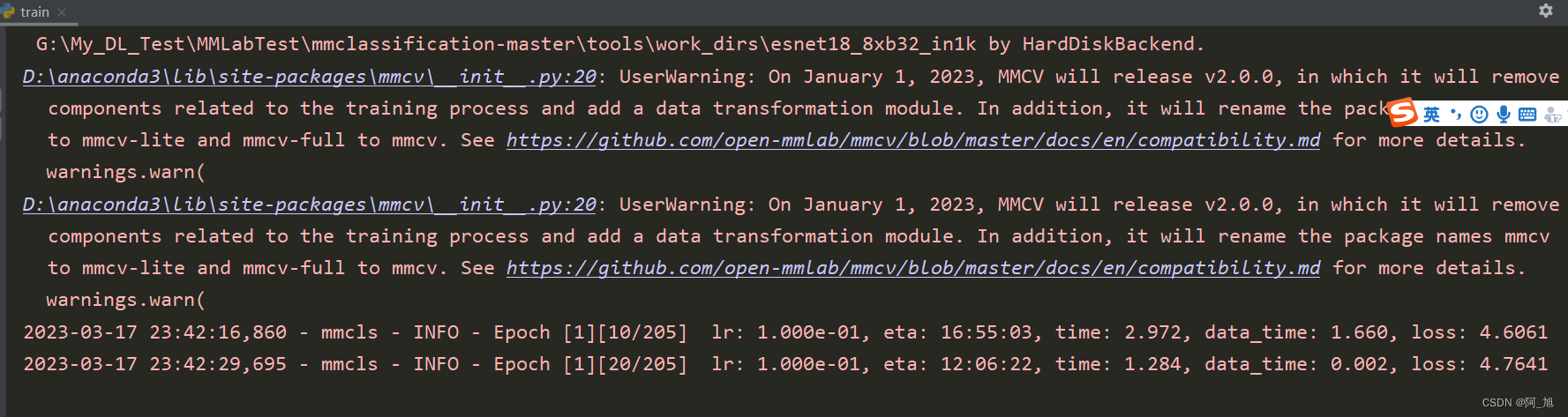
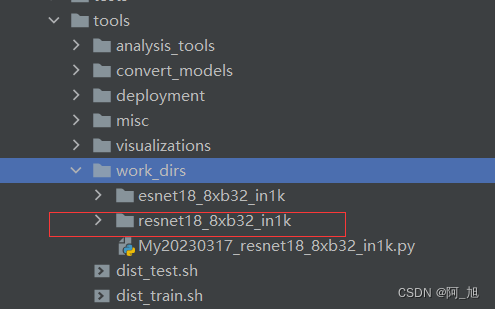
训练的结果会默认存放在tools\work-dirs目录下:(.pth为训练后的模型文件)
模型预测
此处也可以直接下载网上的预训练模型到本地直接进行预测,也可以用刚才自己训练好的模型。
下载链接:https://github.com/open-mmlab/mmclassification
自己训练好的模型默认在下面这个目录下面:
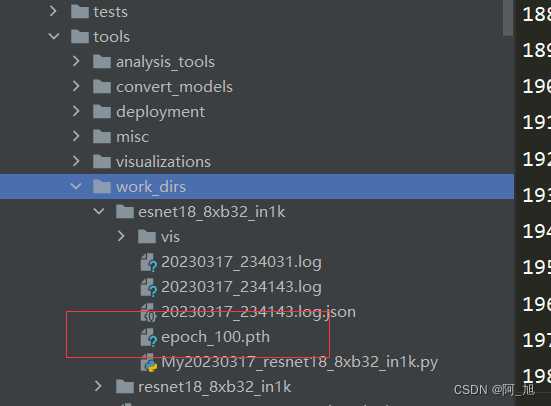
一、单张图片预测
可以使用demo/image_demo.py文件
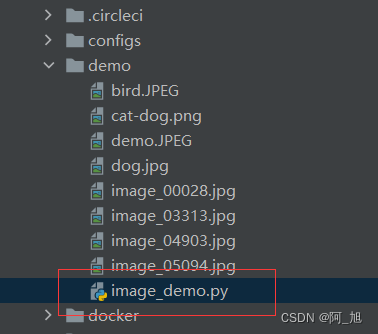
配置下面三个参数:
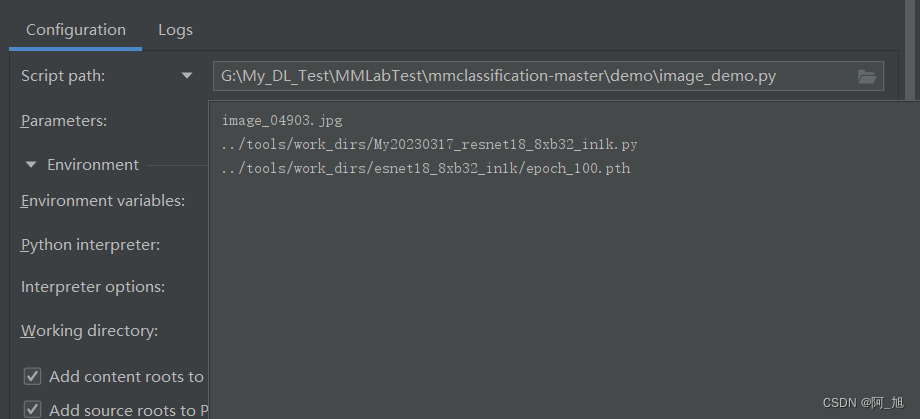
image_04903.jpg # 图片名称
../tools/work_dirs/My20230317_resnet18_8xb32_in1k.py # 训练用的配置文件
../tools/work_dirs/esnet18_8xb32_in1k/epoch_100.pth # 训练好的模型地址
然后运行image_demo.py文件,结果如下:图片上会出现预测图片名称、标签、置信度

二、多张图片预测
使用tools/test.py文件
设置运行参数:(可根据上文参数说明修改相应需要的运行参数)
模型会自动将之前配置文件resnet18_8xb32_in1k.py中test目录下的图片,都进行检测一遍。
./work_dirs/My20230317_resnet18_8xb32_in1k.py # 配置文件路径
./work_dirs/esnet18_8xb32_in1k/epoch_100.pth # 训练好的模型
--metrics #评估参数,自己选择需要看的参数
accuracy
recall
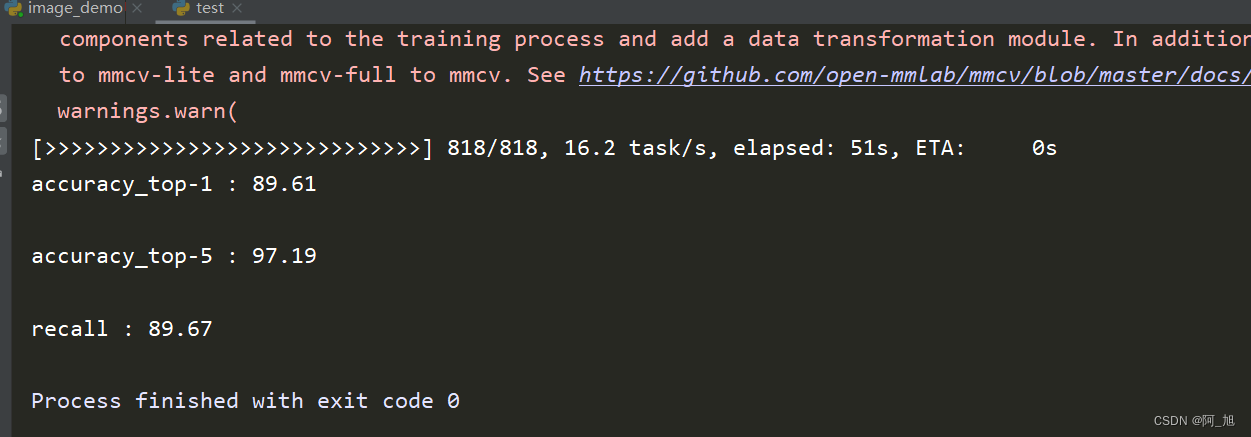
参数设置好后,运行test.py文件,运行结果如下:
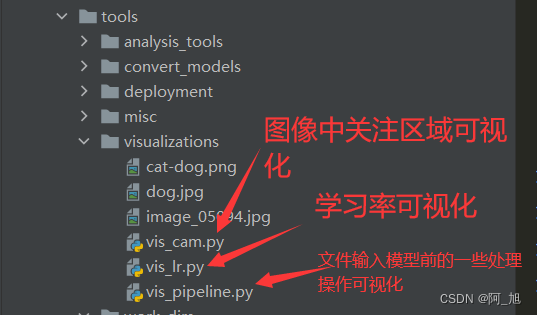
可视化展示
tools/visualizations目录是用于进行结果可视化演示的:
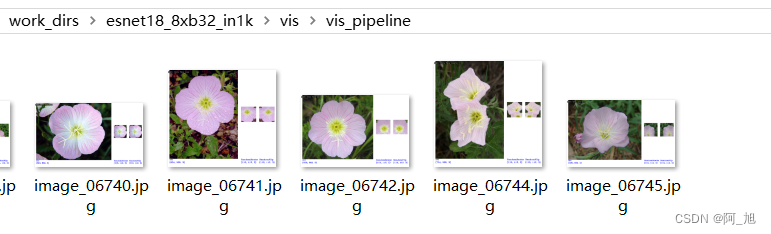
数据增强可视化
输入运行参数,运行vis_pipeline.py文件,会在指定的输出目录下生成相应可视化结果:这个会展示图像在进入模型前的一些处理操作。
注:可根据需要自己设置相应参数。
../../configs/resnet/My20230317_resnet18_8xb32_in1k.py
--output-dir
../work_dirs/esnet18_8xb32_in1k/vis/vis_pipeline
--phase
train
--number
10
--mode
pipeline

特征可视化–vis_cam.py文件
需要额外装一个第三方库:pip install grad-cam
利用训练好的模型,进行图像特征可视化操作,观察模型的注意力在图片的什么位置:
至少需要3个参数:图像路径,模型配置文件路径,训练好的模型路径。
不指定类别的话,默认选择图片所属概率最高的类别进行处理。
target-layers参数可以指定给定层的注意力情况,默认是最后一层网络。
结果显示如下:图片中蓝色部分表示不怎么关注的,红色地方表示比较关注的,可以看到模型的主要注意力都集中在了狗狗的头部。

结果日志分析工具
1.绘制参数曲线、
2.计算模型训练时间
3.计算模型的参数量(不需要训练好模型):配置文件、输入图片大小
绘制参数曲线运行参数示例:
plot_curve ../work_dirs/resnet18_8xb32_in1k/flower-100epoch.json --keys loss
计算模型训练时间参数示例
cal_train_time ../work_dirs/resnet18_8xb32_in1k/flower-100epoch.json
关注GZH:阿旭算法与机器学习,回复:【mmlab实战1】即可获取已经下载好的mmlabclassification源码与demo训练用的数据:数据在mmcls/data目录中,已经放置好了
如果文章对你有帮助,感谢点赞+关注!
欢迎关注下方名片:阿旭算法与机器学习,共同学习交流~