最大值最小值归一化_sklearn官网介绍_防止过拟合W越少越小---人工智能工作笔记0030

然后我们再来看一下,再来说一下归一化
比如:在公司有两个人,一个是W2 他能力强,然后领导给他分配的活还少,
然后一个是W1他能力弱,干的慢,但是领导给他分的活多,这个时候他们一起做一个项目的话,那么
就会出现,W2已经干完活了,在那闲着,然后W1还在赶工对吧,这个时候,怎么调整,呢,肯定不能,让他俩掉个个对吧,在机器学习中,公式是固定的没办法分开,这怎么办呢?
可以这样,我们找两个,能力相当的W2,W1,然后给他俩分配,几乎一样的任务,这样就能保证他俩,几乎一块做完工作了.
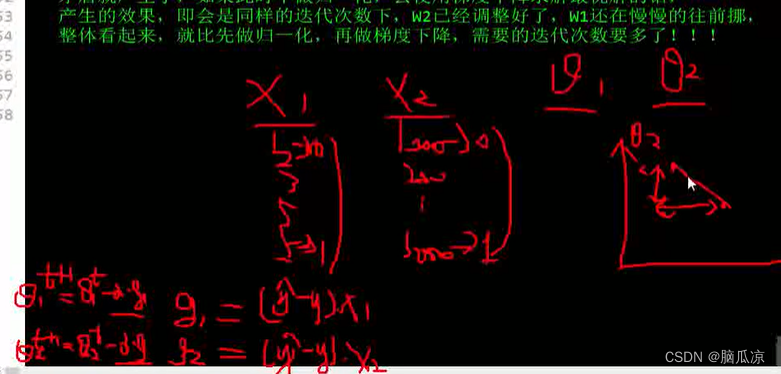
然后比如,我们有两组样本x1 是1 2 3 5 5 ,x2是10000,20000,30000,50000,50000
我们根据y=w0x0这样来说的话,那么x越大,对应的theta就越小对吧,x越小,那么theta就越大,那么
这里如果我们可以让,x1,x2 都差不多大呢?然后可以看到右边画的图,这个时候,如果x1,x2,这两个
样本都可以缩小到同一个范围,并且,不失去原来的意义,那么,最后画出图,就可以是右边这样,那么
他们这个theta t+1 计算的时候,计算出来也差不多,也就是他们走的步长,基本一致,这样就可以让他们几乎在一个时刻进行收敛,一起收敛对吧,这样图画出来就可以几乎是一个直线了比较优美了,这样
就会使得迭代的次数,几乎,相当,同样的迭代次数可以让,所有样本都找到最优解对吧.

可以看到上面就是归一化问题,让一组数据,缩放到 0到1之间,然后再去处理问题.
然后看一下sklearn的官网

可以看到这个首先这sklearn Scikit-learn(简称sklearn)是一个流行的Python机器学习库,提供了各种各样的机器学习算法和工具,使得机器学习的任务更加容易和高效。它是一个开源的项目,由大量的贡献者共同开发和维护。
可以看到他可以解决这个分类问题,比如spam detection垃圾邮件的识别,然后图片的分类,然后使用到的算法有SVM支持向量机,有nearest neighbors邻近算法,有random forest 随机森林对吧.

然后回归这里,regression主要是为了解决,连续的值的问题,其实就是适用于,连续的曲线函数对吧,
比如可以用来预测药物,用来进行股票价格预测.
然后可以看到算法有SVR,支持向量机的回归,然后ridge regression 岭回归,还有lasso 这是lasso算法
然后再来看这个clusterning这个是聚类对吧,这个具体的,可以看到我们之前说
分类问题 的函数 y=ax+b ,然后这个聚类,其实输入的仅仅x的值,x1...xn,对吧,他的做法是,把具有相似特征的个体放到一起对吧,来进行分组可以看到
然后再来看