低内存、高性能,磁盘索引可以这样玩

在 Milvus 社区中,与磁盘索引相关的问题成为近期用户集中询问重点。为了方便用户更深入地了解磁盘索引,我们将从其原理出发,由表及里地介绍如何用好磁盘索引。
Milvus 是世界上最快的向量数据库,在最新版本的 Milvus 中,基于内存的 HNSW 索引可以提供极致的性能体验。然而,Milvus 的目标是支持多种不同的场景,除了性能,我们也追求性价比和可扩展,因此便有了磁盘索引。
基于 DiskANN 的磁盘索引可以在仅使用 1/10 的内存消耗下,发挥出 HNSW 索引 1/3-1/2 的性能能力,能够在千万级别的数据上拿到 ~10ms 的延迟能力。因此,它可以帮助用户在 QPS、Latency 不特别敏感的场景下大大降低资源的消耗。
01.
DiskANN 原理浅析
之前已经有 Zilliz 的同学写过一篇关于 DiskANN 论文的相关文章[1],感兴趣的朋友可以了解一下。
回到原理介绍的部分,DiskANN 的大致结构是在内存中维护一个 PQ,然后原始向量和邻接表以 Vamana 图的结构储存在硬盘里。
Vamana
图的结构有很多种,最早是 2011 年有文章提出链接每个点的最临近的 K 个点。这种策略的空间占用高,并且性能差。
后来大家优化的重点就在于如何去剪枝。2017 年,有篇文章提出了 NSG 图,策略就是如果一个新的点离目标点的距离远于离目标点的邻居,就不链接。即保证对于目标点的邻居,以它为中心,到目标点的距离为半径的圆里边没有别的目标点的邻居。
这种策略减少了每个点的出度,大大加快了查询的速度。
DiskANN 基于的 Vamana 图就是由 NSG 演进而来,具体的改进就是由于 NSG 的裁边机制过于激进导致精度下降,因此引入一个参数 alpha 来控制裁边。具体就是裁边的时候判断的距离乘上这个系数后还是过大才会裁掉。
Build
简单介绍一下 DiskANN 建索引的过程:
首先 DiskANN 会对原始数据采样找到 PQ 的 Pivots,这一步 DiskANN 默认是 256 个 clusters,会根据用户允许的在查询中使用的内存来决定 chunk 数目和大小。然后对原始数据进行 PQ 压缩。
然后 DiskANN 会基于原始数据来构建 Vamana 图,根据用户的允许的在建索引中使用的内存在决定是一次建完还是分批建然后 merge。后者会有较大的性能降低。
然后是把数据都写入磁盘,并删除中间文件。
最后会生成一个从原始数据中随机采样的样本用于 warmup。
Search
首先 DiskANN 会加载磁盘中的索引文件,把 PQ 码表放进内存,然后根据用户的参数开始建立 cache 和 warmup。
Cache 的策略有两种:
取之前的采集的样本进行 query,缓存中间路过的点。目前是用于 KNN search。
在 entrypoint 周围进行 BFS,缓存这些点,目前用于 range search。
Warmup 的方式则是对样本进行 query。
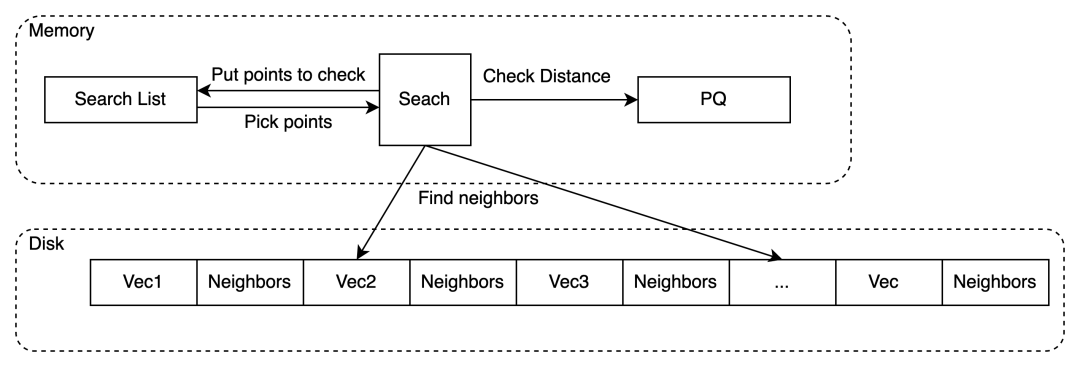
然后就是 DiskANN 的搜索算法,具体做法是:
先根据参数固定一个 search list,把 entry point 放进去。
然后从 search list 每次拿至多 beamwidth 个点,在硬盘中加载向量和邻居。
用 PQ 计算这些邻居到目标点的距离,择优放进 Search List(类似于 Priority Queue)。
一直循环到 search list 被占满。且都访问过。
把途径的所有点收集起来排序取 topK。
02.
DiskANN in Milvus
关于 Milvus 是如何使用 DiskANN 索引的,大致可以用下边的数据链路图表达:
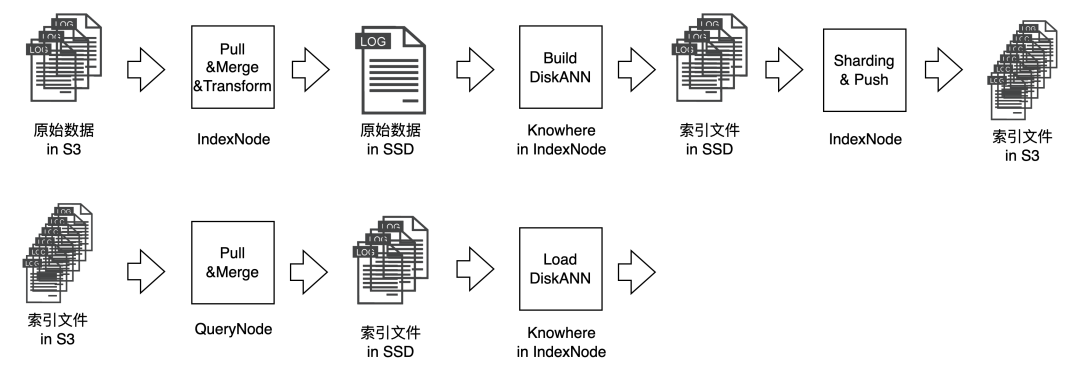
Build 时,IndexNode 会从 MinIO 里抓取原始数据,预处理后放入本地磁盘。然后 DiskANN 会从磁盘中读取文件并生成索引文件。最后由 IndexNode 把建好的索引文件处理后推到 MinIO 里。
Search 的时候,QueryNode 会从 MinIO 里抓取索引文件,与处理后放入本地磁盘。然后 DiskANN 会从本地磁盘中加载少量必要的信息以供查询。
03.
如何用好磁盘索引
适用场景
磁盘索引适用于对性能不是非常敏感,且内存资源有限的场景。在默认场景下,内存的占比是原始数据大小的 1/4,其中 1/8 用作 PQ 码表,1/8 用作 cache。索引的磁盘占用是原始数据的 1.5~2 倍。这些比例都可以通过参数来调节以满足不同场景的需求,后边会具体介绍。
数据类型:目前 Milvus 的 DiskANN 只支持 float 类型的数据。
距离类型:DiskANN 能支持 L2 和 IP 距离。
维度:由于 Milvus 依据原始数据大小划分 Segment,如果维度过小,会导致一个 Segment 里数据行数过多。
DiskANN 的索引主要由原始数据和邻接表组成,过多的行数会导致单个 Segment 索引中邻接表数量变大,从而导致整个索引大小过大。因此 Milvus 的 DiskANN 暂时不支持 16 维以下的向量。因为 DiskANN 会大量访问磁盘,而磁盘的访问都是以一个大小是 4096 的 page 为基本单位的。因此过大维度会引起磁盘访问增大,从而导致性能下降。Milvus 的维度上限为 32768,但是为了获得更好的性能,推荐的最大维度为 1024。
性能瓶颈
磁盘索引的 Search 性能瓶颈一般集中在磁盘 IO 上,因此好的磁盘对于性能的提升几乎是线性的。一般来说 SSD(NVMe) 的性能是 SSD(Sata) 的4-5倍,而 SSD(Sata) 的性能是一般 HDD 的 4-5 倍。
但是磁盘的性能对索引的 Build 性能影响不大。Build 的时候 DiskANN 需要在内存里建图,因此需要约单个 Segment 原始数据 1.7-2 倍左右大小的内存支持。如果内存不够,DiskANN 会分块建图再合并,会造成比较大的 Build 性能损失。
参数调整
关于磁盘索引的相关参数调整可以参见 Milvus 官方文档[2] 。
这里还想分享一个性能上的 trick。一般图算法在数据量增大后,Latencty 的上升会很不明显。因此调整 Segment 大小能对性能产生不小的影响。在 ${MILVUS_ROOT_PATH}/configs/milvus.yaml 里,调大 dataCoord/segment/diskSegmentMaxSize (默认 2G) 会让性能更好。
参考资料
[1]
DiskANN 论文相关文章:https://zhuanlan.zhihu.com/p/394393264
[2]
官方文档:https://milvus.io/docs/disk_index.md
(本文作者刘力系 Zilliz 主任工程师)
