DeepSeek小爆发 DeepSeek小爆发 deepseek属性大爆发

DeepSeek官方刚刚突然宣布:我们发最新版本模型DeepSeek-V3.1啦!
消息一出,一个小时在X上的浏览热度就达到了26万!
据DeepSeek介绍,DeepSeek-V3.1是一款混合型模型,支持“思考模式”与“非思考模式”混合运行,用户可以根据场景需求,灵活切换推理深度,效率和能力两手抓。
得益于深度优化的训练策略与大规模长文档扩展,DeepSeek-V3.1在推理速度、工具调用智能、代码和数学任务等方面均有显著进步。
咱们先捋一下这次新版模型的几大亮点:
·混合思考模式:通过切换对话模板,单一模型即可兼容思考与非思考两种模式。
·更智能的工具调用:通过后训练优化,模型在调用工具和完成Agent(智能体)任务方面的表现显著提升。
·更高的思考效率:DeepSeek-V3.1-Think在回答质量上可与R1-0528媲美,同时响应速度更快。
A
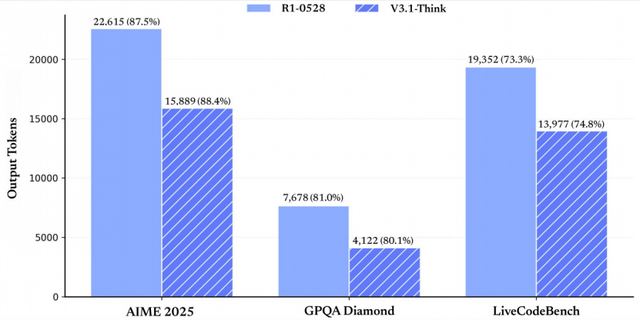
官方放出的测试结果显示,V3.1-Think AIME 2025(美国数学邀请赛2025版)得分88.4%,GPQA Diamond(高难度研究生级知识问答数据集的Diamond子集)得分80.1%,LiveCodeBench(实时编码基准)得分74.8%,均优于老模型R1-0528的表现:87.5%、81.0%、73.3%。
而且,正如下图所示(纵轴是输出token数),V3.1-Think的输出tokens反而大幅减少。
也就是说:V3.1-Think相较于老模型R1-0528,使用更少的tokens,但达到了相似或略高的准确率,在计算资源优化上的优势很明显。
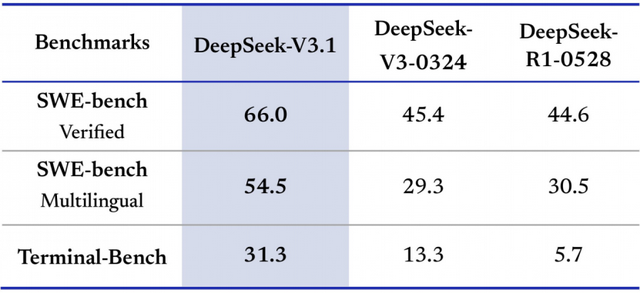
在软件工程和Agent任务基准上的性能提升方面:
·SWE-Bench Verified,DeepSeek-V3.1得分66.0%,远高于V3-0324的45.4%和R1-0528的44.6%,表明其在处理复杂代码任务时更可靠。
·SWE-Bench Multilingual(多语言版本),DeepSeek-V3.1得分54.5%,大幅领先V3-0324的29.3%和R1-0528的30.5%。说明其在多语言支持上有很大进步,可能通过增加多样化训练数据实现,使其更适合全球开发场景。
·Terminal-Bench(使用Terminus 1框架的基准,量化AI Gent在终端(命令行)环境中完成复杂任务的能力,如脚本执行、文件操作或系统交互,模拟真实命令行工作流),DeepSeek-V3.1得分31.3%,优于V3-0324的13.3%和R1-0528的5.7%,在Agent框架下的效率提升,适合自动化运维或DevOps应用。
需要注意的是,DeepSeek V3.1的本次更新,核心在于显著增强了模型的智能体能力,尤其是在复杂推理和工具链协作场景下的实际表现。
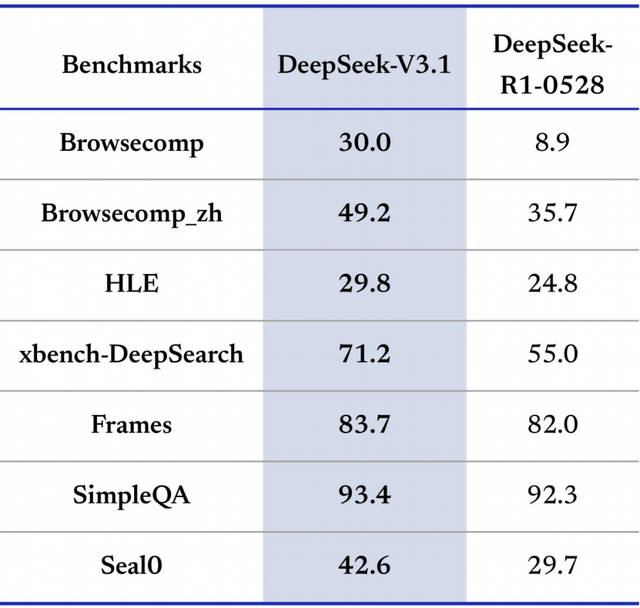
此外,DeepSeek-V3.1搜索Agent、长上下文理解、事实问答和工具使用等领域的性能也表现强势。
DeepSeek-V3.1(基于MoE架构,总参数671B,激活37B)在大多数基准上显著优于R1-0528,在搜索Agent和长上下文任务上的平均提升约20-300%,尤其在工具使用(如xbench-DeepSearch)和事实QA(如SimpleQA)中领先,这意味着它适合构建AI Agent应用,如自动化搜索或代码辅助。
相比R1-0528(专注于推理但效率较低),DeepSeek-V3.1更注重平衡速度与质量,DeepSeek的“Agent时代” 正式拉开帷幕。
在Huggingface上,DeepSeek释放出了更详细的评估结果。
基于官方给出的与前代的测评比较,DeepSeek-V3.1在常规推理和知识问答任务(如 MMLU-Redux 和 MMLU-Pro)上,整体表现稳定提升,非思考和思考模式下的分数均高于V3旧版,基本接近行业顶尖大模型水平。
例如,在 HLE(Humanity’s Last Exam,搜索+Python 复合推理)任务上,DeepSeek-V3.1实现了 29.8% 的通过率,优于自家 R1-0528 版(24.8%),并接近 GPT-5、Grok 4 等国际一线大模型。
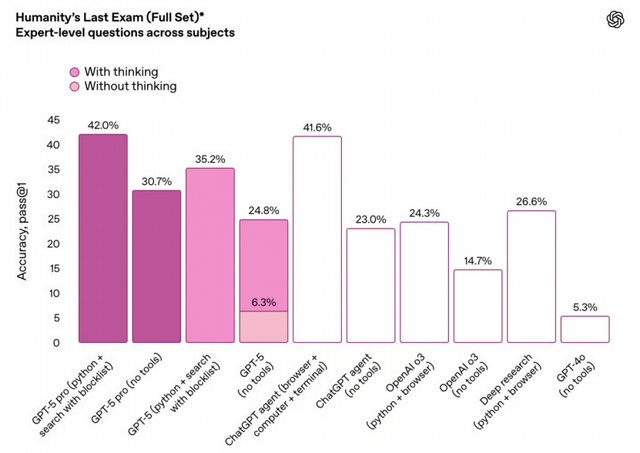
虽然各大模型在评测细节上存在一定差异,但DeepSeek的表现仍具有说服力。
新版模型在网页检索、复合搜索和工具协同场景(BrowseComp、BrowseComp_zh、Humanity’s Last Exam Python+Search、SimpleQA)上有跨越式进步,中文网页搜索和多模态复合推理分数显著超越旧版本。在 SWE-Bench Verified代码评测中,DeepSeek-V3.1以66.0%的成绩大幅领先前代(44.6%),也与 Claude 4.1、Kimi K2等顶级模型保持同一水准。
在Terminal Bench终端自动化测试中,其得分也略高于GPT-5和o3等知名竞品。
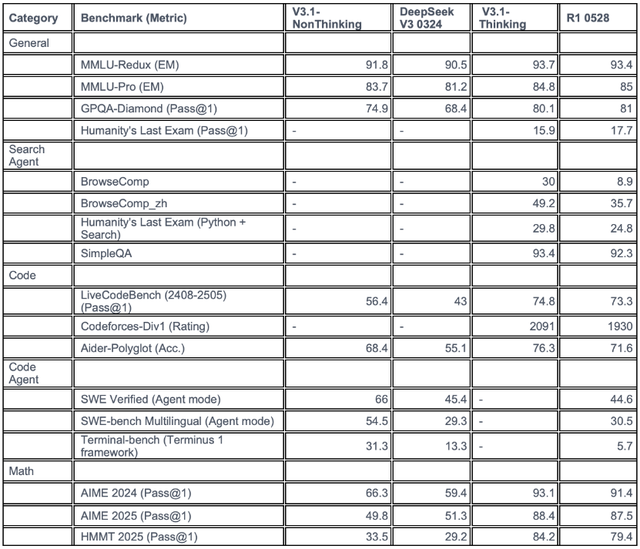
与此同时,DeepSeek-V3.1在代码生成和自动化评测(LiveCodeBench、Codeforces-Div1、Aider-Polyglot、SWE Verified、Terminal-bench)方面,得分也较前代显著提升,特别是在智能体模式下,代码任务通过率和自动化执行能力大幅增强。在AIME和HMMT等高级数学推理和竞赛任务上,DeepSeek-V3.1的表现优于前代产品,思考模式下解题成功率大幅提升。
不过作为通用对话模型,V3.1 并未在所有维度超越前代产品——在部分常规对话和知识问答场景下,R1-0528 依然具有一定竞争力。
B
在具体的性能表现之外,DeepSeek发布新模型,一定会被外界密切关注的当然是价格。
这次,DeepSeek也没有让大家失望。

Input API Price(输入定价),分为两种情况:
·Cache Hit(缓存命中):0.07美元/百万tokens。
·Cache Miss(缓存未命中):0.56美元/百万tokens。
Output API Price(输出定价)为1.68美元/百万tokens。
MenloVentures的风险投资人、前谷歌搜索团队成员Deedy也发推大呼“鲸鱼回来了”。(这哥们在X上有20万粉丝,妥妥的科技界大V。)

除了价格良心之外,DeepSeek-V3.1还首次实现了对Anthropic API的原生兼容。
这意味着,用户可以像调用Claude或Anthropic生态的模型一样,将DeepSeek的集成进现有系统。无论是通过Claude Code工具链还是直接使用Anthropic官方SDK,开发者只需配置API地址和密钥,即可在所有支持Anthropic API的环境下,使用DeepSeek-V3.1提供的推理和对话能力。
从目前的反馈来看,外界对这次发布的反馈还是很好的,尽管它并非“拳打Grok4、脚踩GPT-5”的霸王龙,但它有明确的、清晰的侧重点与优势。
更有意思的是,从两天前DeepSeek默默发了V3.1-Base开始,网友已经再次惊叹于DeepSeek发模型的节奏之舒适、态度之低调。

在其他模型发布往往先炒作规格和性能数据的时候,DeepSeek反其道而行,直接放出模型文件让开发者立即下载测试,然后再补充细节。高效、开发者友好。